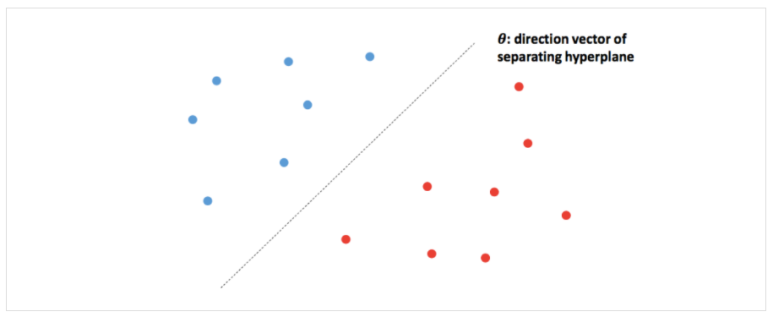
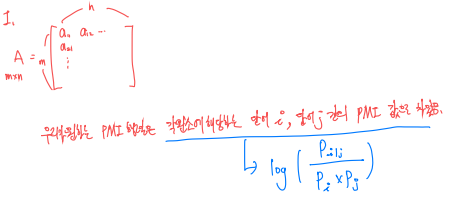
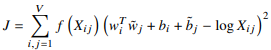잠재 디리클레 할당(LDA)은 주어진 문서들에 대하여 각 문서에 어떤 토픽(주제)들이 존재하는지에 대한 확률 모형이다. 말뭉치 이면에 잠재된 토픽(주제)를 추출함으로써 토픽 모델링(topic modeling)이라 부르기도 한다. 문서들의 토픽 활률 분포로 각각 알아낸 다음 이를 이용해 문서를 임베딩한는 것이다. 참고 자료는 다음과 같다. 1. 글쓴이가 글을 쓸 때 의도를 가지고 쓴다. 2. 그러므로 그 의도에 유사한 주제들이 글 속에 뭉텅이씩 차지하고 있을 것이다. 3. 그리고 주제에 해당하는 단어들이 글 속에 쓰였을 것이다. 특정 주제에 대한 글을 쓸 때 자주 쓰는 단어들 말이다. 하지만, 우리가 볼 수 있는 것은 문서(글) 내의 단어들 뿐이다. 우리는 단어들로부터 문서의 의도를 추출해내고 그 ..