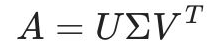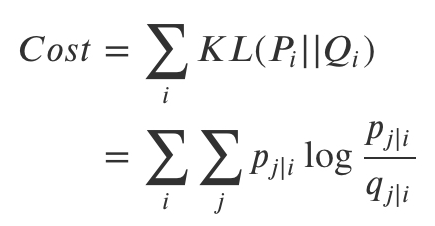형태소 분석기에서 주의해야 할 점이 있다. 만약 우리가 '가우스전자' 라는 기업의 데이터 분석 팀에 속해있다면 우리는 가우스전자라는 토큰은 섬세히 처리해야 한다. 그 이유를 보여주겠다. >>> from konlpy.tag import Mecab >>> tokenizer =Mecab() >>> tokenizer.morphs("가우스전자 텔레비전 정말 좋네요") ['가우스', '전자', '텔레비전', '정말', '좋', '네요'] KoNLPy에서 은전한닢을 이용하여 형태소분석을 하였지만 가우스전자를 가우스,전자 로 나뉘어서 분석해버린다. ==> 단어 임베딩 품질이 떨어진다. 그래서 우리는 '가우스전자' 라는 단어를 사용자 사전에 추가해서 강제적으로 하나의 토큰으로 분석될 수 있도록 할 수 있다. ..