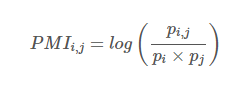'단어-문서 행렬', 'TF-IDF 행렬' '단어-문맥 행렬' , 'PMI 행렬' 과 같은 단어와 단어, 문장간의 등장 빈도를 행렬로 나타내어 단어를 벡터로 표현할 수 있었지만, 차원이 너무 커 계산상의 효율성을 키우기 위해 차원은 축소하되 단어가 담고있는 의미를 보존하기 위해(정교하게 뽑아냄으로써 잠재 의미를 드러내기 위해)잠재 의미 분석이라는 방법이 등장했다. 이는 성능이 아주 뛰어나지는 않지만, 뒤에 나오는 GloVe나 Swivel 과 같은 곳에 행렬 분해 기법으로서 사용된다. PMI는 두 확률 변수 사이의 상관성을 계량화한 지표이다. i 가 일어날 확률, j가 일어날 확률과 i,j가 동시에 일어날 확률을 가지고 다음과 같은 식으로 표현하면, PMI는 i,j가 자주 같이 등장할수록 커..