단어 수준 임베딩 마지막 기법인 Swivel이다.
Swivel(Submatrix-Wise Vector Embedding Learner)은 구글 연구팀(Shazzer et al., 2016)이 발표한 행렬 분해 기반의 단어 임베딩 기법이다.
해당 논문은 다음과 같다.
Swivel은 PMI 행렬을 분해한다는 점에서 단순히 중심단어-문맥단어 행렬을 분해하는 Glove와 차이점을 보인다.
또한 Swivel은 더 나아가 PMI의 단점을 극복할 수있게 설계하였다.
그렇다면 PMI의 단점은 무엇일까?
학습과정에서 i,j 두 단어가 한번도 동시에 등장하지 않는 경우 로그 안의 값이 0이 되어 발산한다는 점이다.
그래서 Swivel의 비용함수는 두가지로 나누니다.
1. 말뭉치에 동시 등장한 케이스가 한 건이라도 있는 경우
2. 말뭉치에 동시 등장한 케이스가 한 건도 없는 경우
1.을 살펴보자

사용된 개념은 다음과 같다.
wiT : 중심단어 i 에 해당하는 행벡터
wj : 문맥단어 j 에 해당하는 열벡터
xij : 단어 i,j의 동시 등장 빈도
f(xij) : 단어 i, j의 동시 등장 빈도에 비례하는 함수내 보정값 (정확한 정의는 글 맨 아래에 있음)
우리가 원하는 것은 비용함수를 줄여나가 업데이트를 하는 것이므로,
f(xij) 가 커질수록, 즉 두 단어 i,j 가 동시등장하는 경우가 많아질수록
wiT와 wj 의 내적값(=코사인 유사도값 = 서로 단어간 의미 유사도값)이
PMI값(두 단어i,j가 동시 등장할 가능성)과 일치하도록 강제해야 한다는 것이다.
정리하면,
단어 i,j가 말뭉치(글)에서 등장하기만 하면 같이 붙어서 나타난다면?
=> 이것은 두 단어가 깊은 의미 관계를 맺고 있다
=> 그렇다면 두 단어 벡터를 비슷한 방향으로 만들어주자
인 것이다.
하지만 단어 i 와 j가 깊은 의미관계를 맺고 있음에도 말뭉치의 성격 때문에 그 관계를 학습하지 못하면 어떡해야 하는가?
즉, '확률' 과 '분포'는 흔하지는 않지만 통계학과 관련 있는 데이터에서는 자주 같이 등장한다.
하지만 우리가 학습한 데이터는 '네이버 영화 리뷰 데이터' 이다.
여기서 저 두 단어간의 관계를 학습할 가능성이 매우 낮다
이런 문제들도 있고 하니깐 2번이 등장했다.
2. 말뭉치에 동시 등장한 케이스가 한 건도 없다. 그러하다면 PMI가 음의 무한대로 발산해버린다.
이를 해결하기 위해 PMI 계산에서 단어i,j의 동시 등장 횟수를 0인경우 1로 가정하고 계산한다.
논문에서 표로 정리해 놓은 부분이다.

2번에만 집중해서 보면
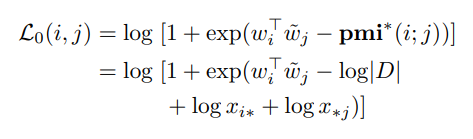
로 되고 여기서 위에 등장한 PMI 속 log(xij)가 0이되어 사라진 것을 볼 수 있다.
여기서 |D|는 말뭉치의 크기(중복을 허용한 말뭉치 전체 토큰 수) 이다.
2번의 성질을 살펴보자.
따로 각각 자주 등장하지만, 주위에 같이 이어서 등장하지는 않는 단어는 어떨까?
예를들어 '밥' 과 '운전' 을 예로 들면 두 단어는 단독으로 자주 등장한다.
하지만 이어서 등장하는 경우는 별로 없다.
이럴때 , 비용함수를 줄이기 위해 커진 양수 log(xi*),log(x*j) 를 만회하기 위해
두 단어 내적값이 조금 작아져야 한다. => 의미상 연관이 줄어든다.
반대로 등장 빈도는 적지만 아까 말한 '확률' , '분포' 의 경우가 있을 수 있으므로
이전에는 두 단어 사이의 관계에 대한 정보를 벡터에 아예 집어넣지 않은 것과는 다르게
어느정도 의미를 부여해주는 성격을 띤다.
왜냐하면 양수 log(xi*),log(x*j) 가 작아지기 때문에 두 단어의 내적값을 약간 크게 해도 학습 손실에는 크게 영향이 없기 때문이다.
코드로 구현해보자.
일단 네이버 영화 , 위키백과, korquad 말뭉치를 합쳐서 사용했다.
|
mkdir -p /notebooks/embedding/data/word-embeddings/swivel
/notebooks/embedding/models/swivel/fastprep
--input /notebooks/embedding/data/tokenized/corpus_mecab.txt
--output_dir /notebooks/embedding/data/word-embeddings/swivel/swivel.data
python /notebooks/embedding/models/swivel/swivel.py
--input_base_path /notebooks/embedding/data/word-embeddings/swivel/swivel.data
--output_base_path /notebooks/embedding/data/word-embeddings/swivel --dim 100
|
mkdir -p를 이용해 swivel 디랙토리를 만들고
입력과 출력에 알맞은 데이터를 넣기만 하면 된다.
학습은 공유서버 GPU로 하려 했지만 tensorflow에 문제가 있어서(버전을 낮춰도 해결되지가 않음)
어쩔 수 없이 본인 노트북 저전력 CPU로 학습했다.
총 3시간 32분이 걸렸다.


학습 이후 파이썬 코드를 통해 코사인 유사도 상위 단어를 뽑아보았다.
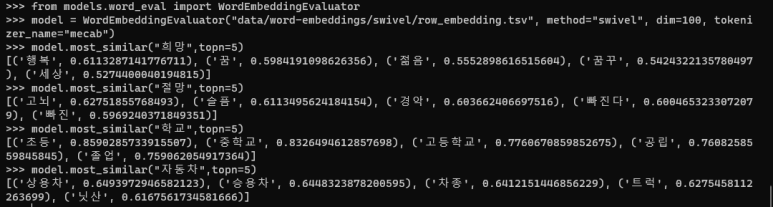
너무나도 깔금한 결과를 만들어 낸다.
f(xij) : 단어 i, j의 동시 등장 빈도에 비례하는 함수내 보정값에 대한 논문속 내용이다.

f(xij)가 xij^1/2 일 때 가장 좋은 결과를 만들어 냈다고 한다.
'Tensorflow 2 NLP(자연어처리) > 단어 임베딩' 카테고리의 다른 글
| [3-9] 단어 임베딩 평가 방법 (0) | 2021.11.13 |
|---|---|
| [3-7] PMI 행렬 만드는 법 (0) | 2021.11.13 |
| [3-6] Glove란? (0) | 2021.11.13 |
| [3-5] Matrix Factorization이란? (0) | 2021.11.13 |
| [3-4] 잠재 의미 분석(LSA,Latent Semantic Analysis) 이란? (0) | 2021.11.13 |