SIF는 (Arora et al., 2016)에서 소개된 단어 임베딩을 문장 수준 임베딩으로 확장하는 기법이다.
해당 논문은 다음과 같다.
A Simple but Tough-to-Beat Baseline for Sentence Embeddings
SIF의 구조를 간단히 정리해 보면 다음과 같다.
1. 문장 내 단어의 등장은 글쓴이가 의도한 주제와 연관이 깊다.
2. 하지만 주제와 관련되지 않은 단어들도 문장 내 포함가능하니 이 부분도 고려하자.
3. 문장 내 등장하는 단어들의 벡터 정보를 가지고(기존 단어 임베딩 기법을 통해 얻을 수 있음)
그 문장을 대표하는 벡터를 만들어 보자.
이다.
이제 논문의 내용을 천천히 따라가 보자
가장먼저 논문 요약부분이다.

여기서 PCA/SVD부분은 python을 통해 이해할 수 있다.
1. discourse vector(=주제 벡터, = context vector) 에 대한 이해가 우선이다.

Ct라는 벡터는 벡터 공간 상에서 slow random walk(random 방향으로 아주 조금씩 이동)를 통해 이동하면서,
단어벡터 Vw(시불변 : time-invariant)와 유사해 질 때, 단어벡터에 해당하는 단어 w를 뱉어낼 확률이 최고에 달하는 성격을 띤다.
2. 이제 문서 단위에서 문장 단위로 접근한다.

우리는 문서 단위 discourse vector ct를 MAP estimation을 이용해 문장 단위 discourse vector Cs로 근사할 수 있다.
+MAP에 대한 설명
https://yngie-c.github.io/machine%20learning/2020/04/04/mle_map/#fn:2
최대 우도 추정 & 최대 사후 확률 추정 (MLE & MAE) · Data Science
본 포스트는 문일철 교수님의 인공지능 및 기계학습 개론 I 강의를 바탕으로 작성하였습니다. 최대 우도 추정 본 챕터에서는 최대 우도 추정(Maximum Likelihood) 에 대해서 알아보겠습니다. 최대 우
yngie-c.github.io
왜냐하면
우리는 문장 안에서 타깃 단어 주위에 어떠한 단어들이 등장하는 지에 대한 정보를 가지고 단어 임베딩함
그러므로 문장 안에서 같이 등장하는 단어 벡터들은 유사하기 때문에 비슷한 공간에 모여있을 것이다.
그러므로 문장 수준 에서 ct들은 별로 이동할 필요가 없어 차이가 별로 없다. 그러므로 이를 Cs 하나로 퉁치자
이제 Cs는 문장 내 단어들을 뱉어내는 벡터이니까 그 문장을 대표한다고 할 수 있다.
이를 주제벡터라고 부르자
그럼 문장 내 단어벡터 w들을 뱉어낼 확률이 가장 높은 주제벡터 Cs를 찾자.
3. 확률로써 나타내자

좌변은 cs가 문장 속의 단어 w를 뱉어낼 확률이므로 이를 높게 만드는 cs를 찾을 것이다.
우변 첫번째 항 ap(w)의 a는 사용자가 알맞게 지정하는 hyperparameter이고,
p(w)는 단어 w가 전체 말뭉치 내에서 등장할 확률이다. 그러므로 자주 등장하는 조사(을/를, 이/가)등이 높은 값을 가질 것이다.
우변 두번째 항은 설명이 좀 필요하다.
가장먼저 cs가 아닌 위에 틸다를 붙였다.
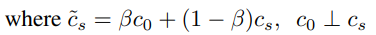
6:15초 경에 나온다.
정리하면, word embedding을 할 때, 우리가 정확히 왜 그런지 알지는 못하는 특정 경향 몇개들을 찾아 낼 수 있는데 그 경향이 바로 c0이다. 저자는 이 경향이 아마 syntactic한 정보나, 보편적인 정보를 담고있다고 보았고,
이 cs에서 일어나는 경향을 담아 '틸다 cs'로 나타낸 것이다.
이를 기하학적으로 이해하면

다음과 같이 c0의 영향 정도를 조절 가능하기 때문에 다음과 같이 나타냈음을 볼 수 있다.
이제 두번째 항을 이해해 보면,
주제벡터와 w에 해당하는 단어벡터 Vw가 유사할수록(내적값이 클수록) 그 값이 커진다. 즉, 이 부분은 주제와 단어가 얼마나 연관성이 있는지를 나타내는 항이다.
그리고 Z(문장 내 모든 단어 각각 주제벡터와 내적하고 그 값들을 합한 후 exp 취해줌)로 나누어주면 확률로써 표현하는 것이 가능해진다.
저 식을 정리하면
주제벡터에서 문장 내 단어w가 튀어나올 확률 = 말뭉치 전체에서 단어 w가 튀어나올 확률 + 주제벡터와 단어벡터vw가 유사한 정도(주제벡터와 단어벡터 Vw가 유사할 수록 w가 튀어나올 가능성이 크니까)
로 정리할 수 있다.

이제 저 확률의 최댓값을 찾을 것인데
문장 내에서 단어와 주제벡터를 뽑을 확률은 모두 독립이여서 다 확률을 누적으로 곱해줘야한다.
하지만, 그러면 값이 너무 작아지기 때문에 양변에 log를 취해 덧셈으로 변환한다.
또한 이 log 변환은 log-linear으로 이어진다.
해당 설명은 다음에서 이해할 수 있다.
아래 노란색 밑줄 문장내 정의를 활용하기 위해 테일러 급수를 통해 식을 간소화 시킨다.

이후 치환을 통해


다음과 같이 나타내는 것이 가능하다. 논문속에서는 (a=0.0001 로 놓았다)
이를 요약하면,
문장을 나타내는 주제 벡터는 문장 내 단어벡터와 그 단어에 해당하는 가중치를 곱해 만든 새로운 벡터들의 합에 비례한다는 것이다.
그리고 이 식을 이용해 문서 내 모든 문장에 해당하는 discourse vector Cs를 구하고 행으로 쌓아
행렬로 만든다음, SVD를 진행한다. 그중 가장 큰 정보를 가진 principal components를 원래 행렬에서 빼서,
각 주제벡터들간의 유사도를 줄이고, 차이점을 키워서 문장벡터로써의 품질을 높인다.
이는 저자가 직접 배포한 코드를 통해 자세히 이해 가능하다.
GitHub - PrincetonML/SIF: sentence embedding by Smooth Inverse Frequency weighting scheme
sentence embedding by Smooth Inverse Frequency weighting scheme - GitHub - PrincetonML/SIF: sentence embedding by Smooth Inverse Frequency weighting scheme
github.com
SIF의 가중치를 더 살펴보면,
희귀한 단어(p(w)가 작음)일수록 높은 가중치를 부여해 해당 단어 벡터의 크기를 키운다는 것을 알 수 있다.
이는 정보성이 높고, 희귀한 단어에 가중치를 높게 주는 TF-IDF와 유사하다.
또한 문장 내 단어의 등장 순서를 고려하지 않기 때문에 bag of words 가정과도 연결된다.
이해에 도움을 준 자료
https://gxli97.github.io/2018/06/15/randwalk/
Notes on RAND-WALK - A Latent Variable Model Approach to Word Embeddings
A personal website.
gxli97.github.io
'Tensorflow 2 NLP(자연어처리) > 문장 임베딩' 카테고리의 다른 글
| [4-5] 잠재 디리클레 할당(LDA, Latent Dirichlet Allocation)이란? + 베이즈 정리,깁스 샘플링 (0) | 2021.11.13 |
|---|---|
| [4-4] Word2Vec에서 Doc2Vec까지 (0) | 2021.11.13 |
| [4-3] 잠재 의미 분석(LSA), TF-IDF를 이용한 문서 임베딩 (0) | 2021.11.13 |
| [4-2] PCA(주성분 분석)와 SVD(특이값 분해) 차원축소를 완벽하게 이해하기 (0) | 2021.11.13 |