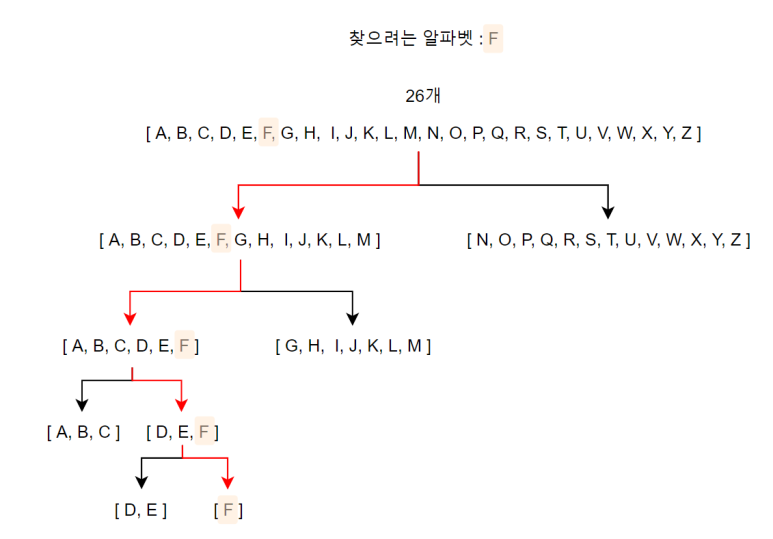
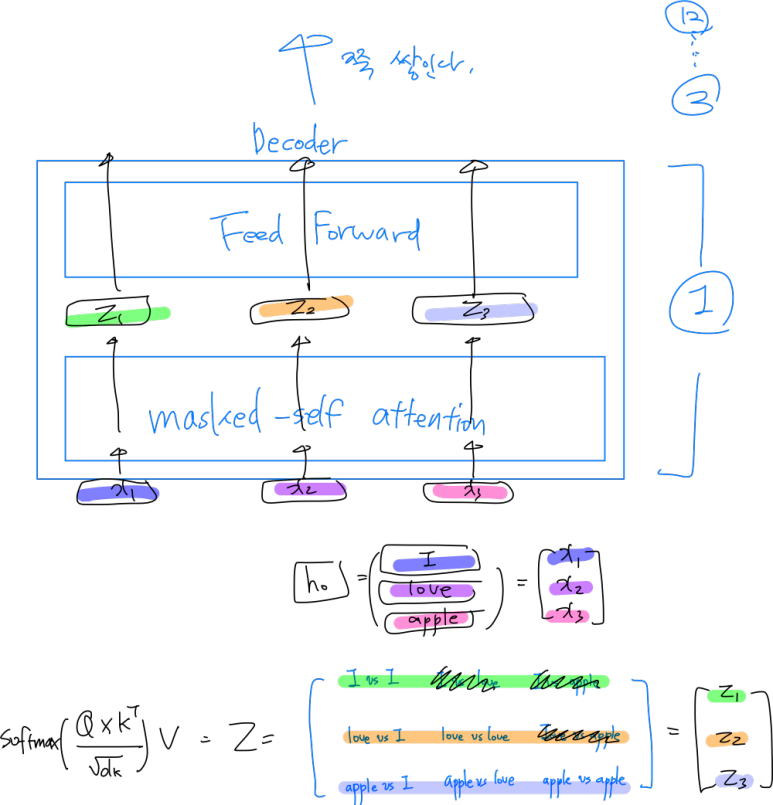
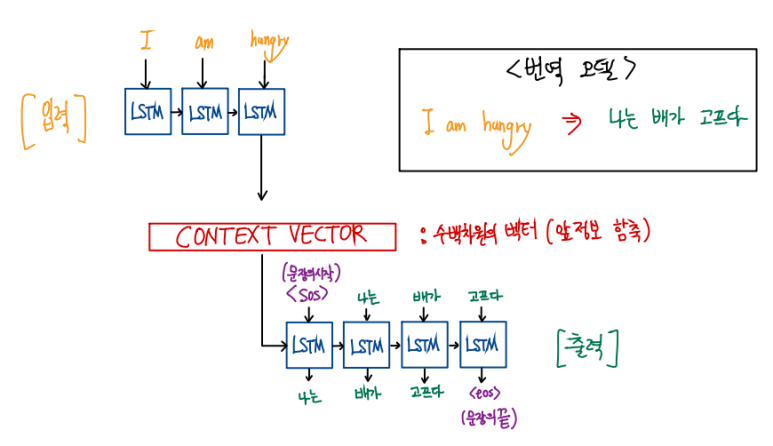
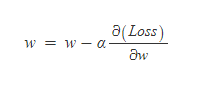비용함수로 자주 사용되는 Cross Entropy에 대해서 깊은 이해를 하게 해주는 영상을 발견했다. ( 자막도 잘 나와있어서 좋다. ) https://www.youtube.com/watch?v=PtmzfpV6CDE https://www.youtube.com/watch?v=2s3aJfRr9gE | 정보량 세상에는 다양한 종류의 정보들이 있다. 이 정보들을 하나의 기준으로 평가하고 싶은데 어떤 기준이 좋을 것인가? A라는 사람이 B라는 사람에게 정보를 전달할 것인데 보내고자 하는 정보의 양(정보량)을 수치화 할 수 있는 방법이 있을까? 일단 정보들을 하나의 기준으로 평가하려면 정보들을 전달하는 방식이 동일해야 할 것이다. 어떤 정보는 문자로 보내고, 어떤 정보는 숫자로 보내면 이 둘 정보..