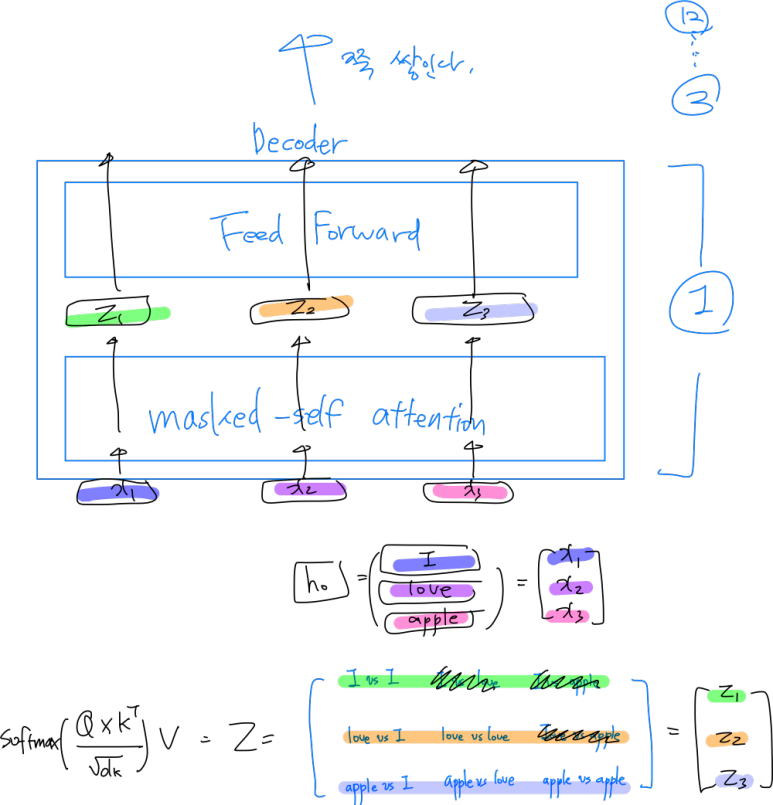
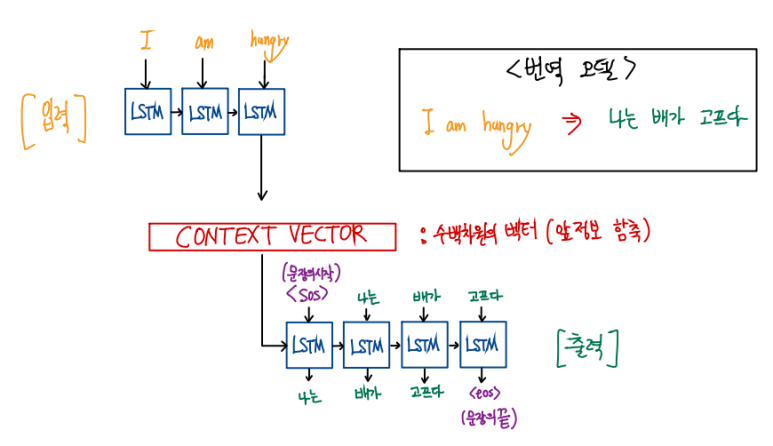
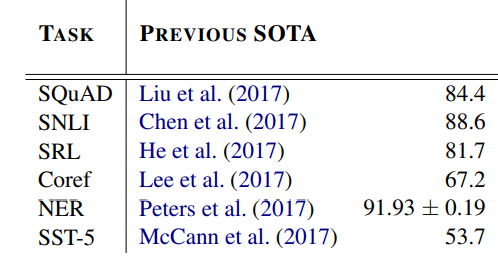
목차 1. 간단 요약 2. 논문 분석 1. 간단 요약 최근 2020년에 발표된 GPT-3가 뛰어난 성능을 보여주고 있다. https://twitter.com/i/status/1284801028676653060 트위터에서 즐기는 Paras Chopra “I made a fully functioning search engine on top of GPT3. For any arbitrary query, it returns the exact answer AND the corresponding URL. Look at the entire video. It's MIND BLOWINGLY good. cc: @gdb @npew @gwern” twitter.com 다음과 같이 어떠한 질문을 하든지 척척 답해내..