LSTM에 대한 설명은 구글에 검색하기만 한다면, 이해하기 좋게 자세하게 설명된 글들을 찾아 볼 수 있다.
하지만, 코드로 구현된 LSTM셀을 보았을 때, 벡터 하나하나들이 어떻게 이동하고, 출력되고, 변형되는지에 대한 이해는 따로 설명이 필요해 보였다. 왜냐하면 우리는 텐서플로우 keras sequential로 생성한 LSTM셀의 input에 2차원 행렬을 굳이 reshape를 하여 3차원 행렬을 집어넣기 때문이다.
그래서 그냥 대충 넘어가는 사람들은 LSTM의 input에 3차원 행렬을 넣으니까 행렬 자체가 LSTM셀에 바로 들어가는 줄 착각하기도 한다. 하지만, 각 LSTM에는 벡터가 들어간다! 그렇다면 어떻게 들어가는가? 를 풀어서 설명해 보겠다.
목차
1. LSTM review
2. LSTM의 input 형태 및 예시
3. 여러가지 예시
4. 모델 학습(fit)과정에서 epoch과 batch_size 결정
5. LSTM의 input(Sample)의 벡터 하나하나의 흐름
6. LSTM의 분류모델 예시

가장먼저 LSTM을 잘 설명해 놓은 사이트를 소개한다.
(영어 원문)
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
(번역)
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
Long Short-Term Memory (LSTM) 이해하기
이 글은 Christopher Olah가 2015년 8월에 쓴 글을 우리 말로 번역한 것이다. Recurrent neural network의 개념을 쉽게 설명했고, 그 중 획기적인 모델인 LSTM을 이론적으로 이해할 수 있도록 좋은 그림과 함께
dgkim5360.tistory.com
(lstm과 rnn)
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN과 LSTM을 이해해보자! · ratsgo's blog
이번 포스팅에서는 Recurrent Neural Networks(RNN)과 RNN의 일종인 Long Short-Term Memory models(LSTM)에 대해 알아보도록 하겠습니다. 우선 두 알고리즘의 개요를 간략히 언급한 뒤 foward, backward compute pass를 천천
ratsgo.github.io
LSTM은 시간에 따른 변화가 있는 값(시계열)을 예측하는데 있어 좋은 성능을 보인다.
또한 LSTM으로 classification도 가능하다.
이제 코드로 접근해서 흐름을 알아보자.

튜토리얼은 다음과 같다.
1. LSTM Input Layer (LSTM input층)
2. Example of LSTM with Single Input Sample (단일 input Sample의 LSTM)
3. Example of LSTM with Multiple Input Features (다중 인풋 Featuers의 LSTM)
4. Tips for LSTM Input (LSTM input 팁)
model = Sequential()
model.add(LSTM(32, input_shape=(50, 2)))
model.add(Dense(1))
다음과 같이 텐서플로우의 keras Sequential로 신경망을 생성한다.
( keras Sequential() 관련 링크 : https://www.tensorflow.org/guide/keras/rnn?hl=ko)
Keras를 사용한 반복적 인 신경망 (RNN) | TensorFlow Core
ML 커뮤니티 데이를 놓쳤습니까? 수요에 대한 모든 세션 시계 보기 세션을 Keras를 사용한 반복적 인 신경망 (RNN) 시작하기 RNN (Recurrent Neural Network)은 시계열 또는 자연어와 같은 시퀀스 데이터를
www.tensorflow.org
그리고 output을 Dense 1차원으로 만든다.

LSTM : LSTM 셀을 생성한다는 뜻이고
32 : 32개의 node를 생성한다는 뜻이고
input_shape = (50, 2) : timestep을 50으로, 입력의 feature가 2라는 뜻이다.
그림으로 그려보면 다음과 같다.

이때, timestep은 뭐시고, feature는 뭐실까?
이를 이해하려면 LSTM의 Input행렬을 뜯어보아야 한다.
결론부터 말하면, LSTM의 input행렬은 '무조건' 3차원이여야 한다.

+설명 덭붙이기 위한 사이트
https://towardsdatascience.com/predicting-stock-price-with-lstm-13af86a74944
Predicting Stock Price with LSTM
Machine learning has found its applications in many interesting fields over these years. Taming stock market is one of them. I had been…
towardsdatascience.com
1. Samples : 몇개의 time steps을 하나의 뭉텅이 데이터로 만들것인지 정하고 나누었을 때, 하나의 뭉텅이 데이터를 sample이라고 한다.
+ batch size : input을 받아오고 그에 따라 output이 나오고 그에 따른 loss 값을 줄이기 위한 가중치 업데이트를 할때 한번 업데이트를 하는데 사용하는 샘플들의 개수
=> 100개의 샘플이 있다고 칠 때, batch size를 1이라 두면 batch는 100개가 된다. batch size를 100이라 두면 batch는 1개가 된다.
2. Time Steps : 한 개의 time step은 샘플(데이터) 내에서 관측하는 한 시점(여러 시간중에 특정 시간)
3. Features : 각 타임스텝에서 특징의 개수(예를들어 받아오는 센서의 개수)
=> LSTM input 벡터의 형태 [ (1) , (2) , (3) ] 중에
1. Sample의 개수가 (1)에 해당
2. 하나의 샘플 안의 Time step의 개수가 (2)에 해당
3. Feature의 개수가 (3)에 해당
[시각화]







로 설명 할 수 있다.

1. 단일 입력 샘플의 LSTM(feature 한개)
0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0라는 시간 당 데이터가 있다.
이를 일단 NumPy array로 만들어주자
from numpy import array data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
하지만 LSTM의 input은 3차원이어야 한다.
reshape을 통해 변환해주자.
data = data.reshape((1, 10, 1))
그럼 이제 LSTM 셀의 input 형태를 다음과 같이 꾸며주면 된다.
model = Sequential() model.add(LSTM(32, input_shape=(10, 1))) model.add(Dense(1))그림으로 설명하면 다음과 같다.


즉, timestep을 10으로 함으로써 전체 시간의 데이터를 하나의 샘플로 간주하면,
2. 다중 입력 샘플의 LSTM (feature 여러개)
from numpy import array
data = array([
[0.1, 1.0],
[0.2, 0.9],
[0.3, 0.8],
[0.4, 0.7],
[0.5, 0.6],
[0.6, 0.5],
[0.7, 0.4],
[0.8, 0.3],
[0.9, 0.2],
[1.0, 0.1]])
data = data.reshape(1, 10, 2)첫째 열은 특징1의 시간에 따른 변화가 행으로써 보여지는 것이고,
둘째 열은 특징2의 시간에 따른 변화가 행으로써 보여지는 것이다.
그렇다면 우리는 모델을 그에 맞게 만들어 주면 된다.
model = Sequential()
model.add(LSTM(32, input_shape=(10, 2)))
model.add(Dense(1))
더 나아가보자!
3. 다중 id의 다중 입력 샘플의 LSTM (받는 상황 여러개, feature 여러개)
예를 들어 어떤 사람이 센서 2개의 값을 10초동안 받아온다. 그런 경우는 위의 2번과 같다.
하지만 그 받는 사람이 한사람이 아니라 여러사람이라면?
사람마다 받아오는 센서 값이 다를 것이다.
그렇다면 어떻게 될까?
사람1의 센서1,2의 시간 5초동안 초당 센서 값 A = [[0.1, 1.0], [0.2, 0.9], [0.3, 0.8], [0.4, 0.7], [0.5, 0.6]]
사람2의 센서1,2의 시간 5초동안 초당 센서 값 B = [[0.6, 0.5], [0.7, 0.4], [0.8, 0.3], [0.9, 0.2], [1.0, 0.1]]이라고 할 때, 우리는이를 학습을 위한 입력으로 넣기 위해 하나로 붙일 수 있다.
방법은
data = np.concatenate((A,B),axis=0 #생략가능)하면 될 것이다.
그럼 다음과 같이 보일 것이다.
from numpy import array
data = array([
[0.1, 1.0],
[0.2, 0.9],
[0.3, 0.8],
[0.4, 0.7],
[0.5, 0.6],
[0.6, 0.5],
[0.7, 0.4],
[0.8, 0.3],
[0.9, 0.2],
[1.0, 0.1]])
data = data.reshape(2,5,2)이때 우리는 reshape를 (2,5,2)로 해주면 된다.
그럼 다음과 같이

3차원 벡터로 사람1, 사람2 당 신호값으로 쌓이게 된다.
이제 이 입력 데이터에 맞게 모델을 수정하면 다음과 같을 것이다.
model = Sequential()
model.add(LSTM(32, input_shape=(5,2)))
model.add(Dense(1))
이렇게 만들어진 신경망을 학습할 때
model.fit(data': 샘플들을 열 방향으로 쌓은 것', '샘플들을 LSTM 셀에 집어 넣었을 때, 각각 샘플들에 대해 나오길 원하는 output vector들을 열방향으로 쌓은것' , epochs = '전체 데이터를 몇번 반복해서 학습할 것인가?', batch_size = '몇개의 샘플을 하나의 batch("한번 가중치 업데이트를 할 때 사용할 샘플들의 뭉텅이")로 할 것인가?')다음과 같이 해 볼 수 있다.

여기서 문제가, 우리는 LSTM에 행렬을 input으로 넣어준다. 하지만 LSTM의 각 input은 벡터이다.
이 벡터는 어떻게 들어가는가?
그에 대한 명쾌한 설명은 다음에서 찾을 수 있었다.
https://stackoverflow.com/questions/38714959/understanding-keras-lstms
Understanding Keras LSTMs
I am trying to reconcile my understand of LSTMs and pointed out here in this post by Christopher Olah implemented in Keras. I am following the blog written by Jason Brownlee for the Keras tutorial....
stackoverflow.com
저 사이트에서 가장 맨 앞에 있는 Answer을 읽어보면 완벽하게 이해가 가능하다.
꼭 다 읽어보는 것을 추천한다. 시야가 넓어진다.
그중에서 벡터 흐름만 가볍게 설명하겠다.
3.번의 id가 여러개인 경우 벡터의 흐름은 다음과 같고,
나머지는 축소버전으로 쉽게 이해 가능 할 것이다.
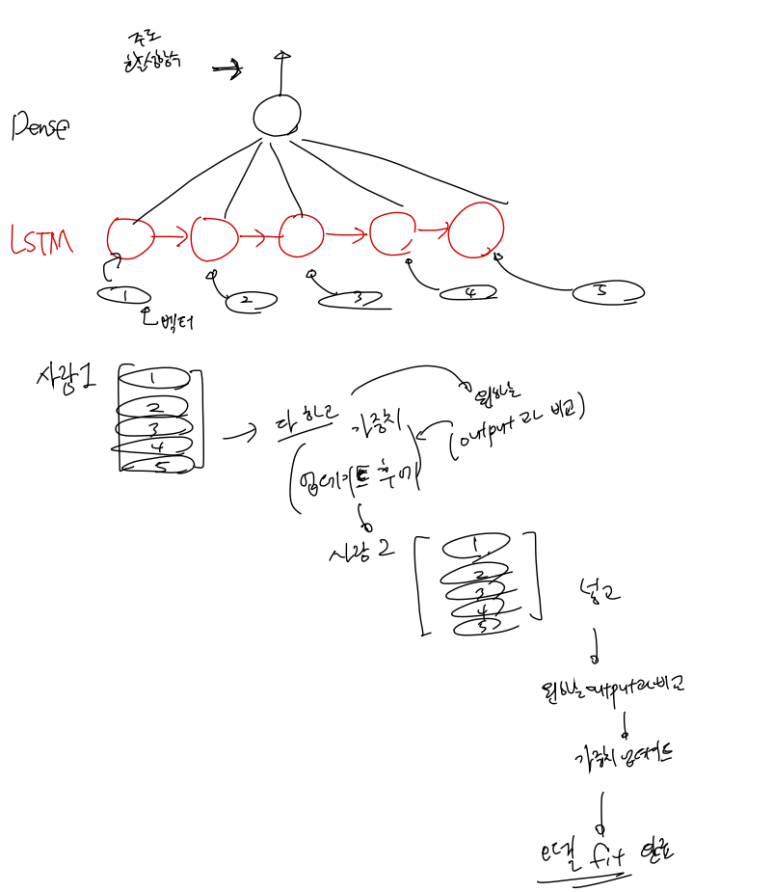
벡터 흐름은 다음과 같이 이해 가능하다.
저렇게 한다면 우리는 1,2,3,4,5 뒤에 6의 경우를 output이라 하고 가중치 업데이트,
2,3,4,5,6 뒤에 7의 경우를 output이라 하고 가중치 업데이트,
이를 쭉 반복하여 fit하였을때 이 모델은
만약 100까지 있다고 친다면, 96,97,98,99,100 을 넣어주면 그 output이 101의 예측치를 의미하게 되고 우리는 시계열을 예측하는 모델을 만드는 것이 가능해진다.

게다가 LSTM으로 classfication을 하고싶다면(현재 얻어오고 있는 신호가 사람1, 사람2인지 구분하는)

다음과 같이 구성하고,
1. 그 output을 input이 사람 1이면 [1,0] , input이 사람 2이면 [0,1]이 되도록
output과 target 값의 오차를 줄이는 과정을 통해 모델을 학습한 이후에,
3. 특정 신호가 담긴 행렬을 만들어 저 모델에 집어넣은다면,
3. 그 output으로 사람1,사람2 를 구분하는 것이 가능 해 질 것이다.
물론 여기에 양방향 LSTM을 쓴다면 성능이 향상될 것이다.