ElMo(2018)가 세상에 나오고 부터 pre-trained word represetation 에 대한 인식이 늘어남에 따라 NLP 모델의 성능이 급등하기 시작했다.
ELMo는

목차
1. RNN과 LSTM review
2. ELMo의 간단한 요약
3. 논문 분석
-개요
-세부내용
RNN
(hidden state)h가 직전 시점의 (hidden state)h의 영향을 받아 갱신됨으로써
이전 상태의 정보를 받아 올 수 있게 됨
⇒ 이전에 언급한 단어들도 기억할 수 있게 되어 문맥 고려가 가능해짐
RNN의 자연어처리에서의 사용
인풋을 벡터로 받아옴
⇒ 그에 따른 출력이 원하는 알파벳이 오도록 추정치와 실제값의 오차를 가지고 모든 매개변수 업데이트
뒤에서 부터 역전파 방식으로 하나하나씩 업데이트(GD사용)
but, h는 이전 상태와 현재 상태를 이어주지만 그 거리가 너무 멀게 되면 gradient vanishing 발생
(0<=1인 값을 계속 곱하니 값이 작아질 수 밖에 없음)
이를 해결하기 위해 hidden state 에 cell-state 추가한것이 LSTM
LSTM
gradient vanishing 을 보완하기 위해 다음으로 정보를 넘길 때, 손실이 덜 일어나는 통로 하나를 더 뚫어주어 따로 뒤로 전달한다. 전달값은 이전 h와 새로운 입력값에 따라 계속 보충된다.
더 나아간 것이 양방향 LSTM
RNN이나 LSTM은 입력 순서를 시간 순대로 입력하기 때문에 결과물이 직전 패턴을 기반으로 수렴하는 경향을 보임. 이 단점을 해결하는 목적으로 양방향 순한신경망이 제안됨
그래서,
기존의 LSTM 계층에
(1) 역방향으로 처리하는 LSTM 계층을 추가한다. 최종 은닉 상태는 두 LSTM 계층의 은닉 상태를 연결한 벡터를 출력한다. 연결 이외에도
(2) 더하거나
(3) 평균을 내는 방법 등 다양하게 적용할 수 있다.

ELMo의 목적은 단어 임베딩의 품질 향상이다.
그들이 말하는 높은 품질의 단어 임베딩이란 다음과 같다.
1. 단어의 복잡한 쓰임새가 단어 임베딩에 함축되어 있어야 한다.
2. 다의어(배,눈 등..)는 의미에 따라 서로 다른 벡터를 부여해야 한다.
그래서 ELMo(Embeddings from Language Model)는 순방향, 역방향 LSTM셀을 모두 사용한다.
양방향 RNN과는 달리 biLM(Bidirectional Language Model)을 이용한다.
두개의 차이는
'양방향 RNN은 현재 위치의 값을 예측하기 위해 이전값과,이후값을 모두 사용하여 훈련'한다고 할 수 있고,
'biLM은 각각 순방향, 역방향 LSTM으로 현재 위치의 값을 예측하고, 두개를 더해 ELMo로 사용한다.'고 볼 수 있다.
그림으로 표현하면 다음과 같다.
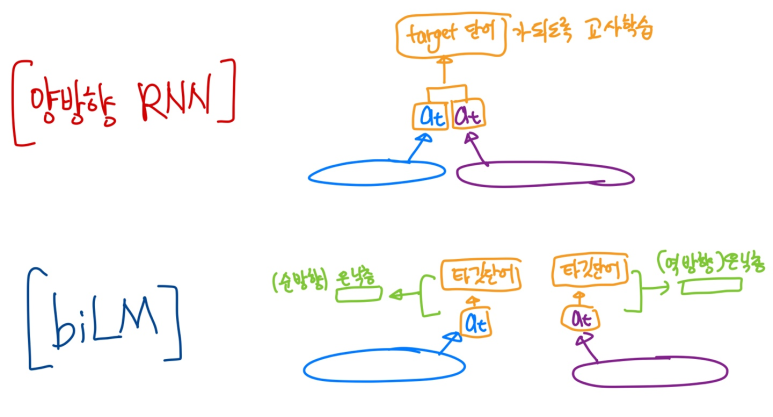
양방향 RNN vs biLM
순방향, 역방향 LSTM셀을 모두 사용하는 이유는 무엇인가?
Word2Vec은 window내의 몇개의 단어만 사용하여 단어 임베딩을 한다.
결국, 단어 임베딩 과정에 (문장 전체를 포괄하는) 문맥 정보를 잃게 된다.
이를 해결하기 위해 ELMo는 순방향, 역방향 LSTM셀을 모두 사용하였고,
(1) 문장 내 모든 단어를 학습과정에 넣어
(2) 문맥 정보를 함축한 농축벡터를 각 단어마다 만들어 낸 후
(3) 그 벡터를 기존의 단어벡터와 더해
(4) 문맥 정보도 포함되어 다의어를 구분하고(단어의 의미에 따라서 문장 내에는 다른 단어들이 등장하므로), 단어의 문장 내 쓰임새 정보를 함축한 단어벡터를 만들어 내었다.
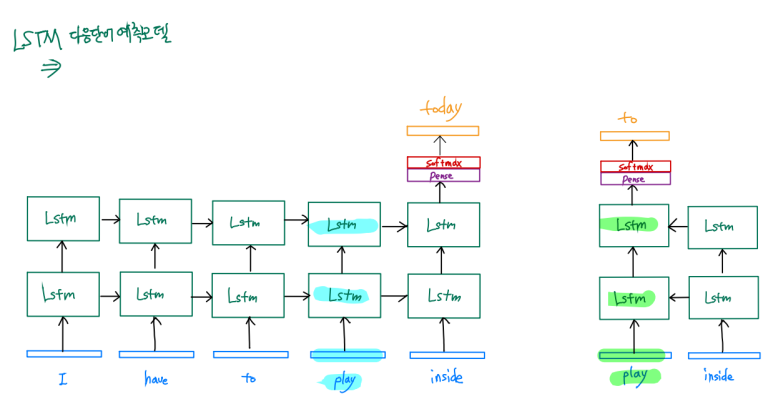
그 과정을 그림으로 나타내면
1. 문장 : I have to play inside today
2. 순방향, 역방향 LSTM 셀 은닉층 학습
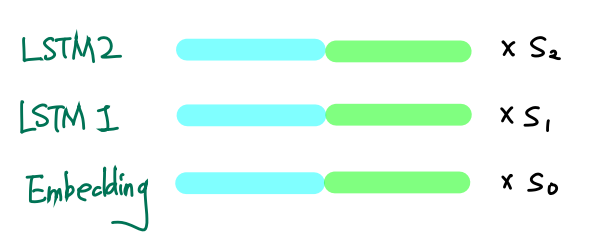
3. 두 은닉층 정보를 합치고 가중치 hyper parameter추가
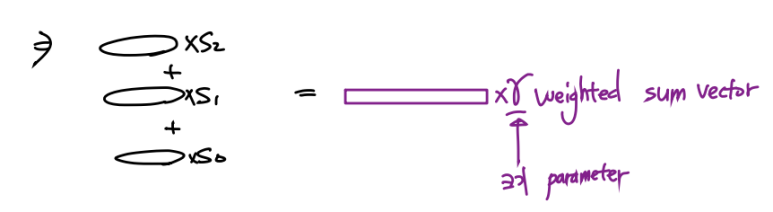
4. 가중합하고, 크기조절 hyper parameter 추가
5. ELMo 벡터와 기존벡터를 더해 downstream task에 사용
으로 나타낼 수 있다.

1. 개요

1. 단어의 복잡한 쓰임새 특성과, 다의어 구분이 가능해야 한다.
2. biLM을 사용하며 학습하였고, 이를 통해 얻은 결과는 NLP의 six challenges에 대해 높은 성능을 나타내었다.
[4-6] Six challenges(benchmarks) in NLP
NLP (natrual language processing) 에는 성능을 측정하기 위해 많이 쓰는 과제들이 있다. Elmo에서 사용한 6개를 소개한다. 1. SQuAD (Standard Question Answering Dataset) (독해 이해 reading comprehensio..
nlp-study.tistory.com
3. Pre-trained word representation은 NLP,NLU에 아주 중요하다.
2. 세부내용

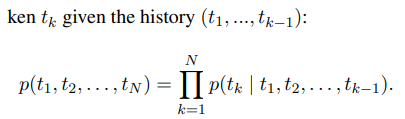
forward language model의 k번째 단어 tk는 k번째 이전 단어들을 모두 고려해 만들어진다.

backward language model의 k번째 단어 tk은 k번째 이후 단어들을 모두 고려해 만들어진다.


biLM은 양 language model을 combine 하고, 로그우도를 jointly maximize(각각 maximize) 한다.


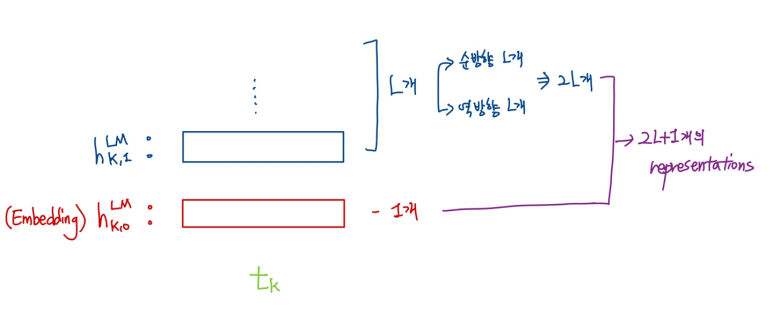
Rk는 k번째 토큰(단어)의 biLM결과와,embedding 벡터를 의미한다.

이제 각 층에 따라 s(가중치)를 정하고, 최적화를 위해 크기조절 scalar parameter 을 부여한다.

가중치 s
가중치 s에 따라 각 층의 가중치를 부여할 수 있다.
이들에 따르면
높은 층의 LSTM(출력과 가까이 있는)셀의 h는 context-dependent(문맥고려)경향의 정보를 담고있으며.
낮은 층의 LSTM(입력과 가까이 있는)셀의 h는 syntax(구문분석)경향의 정보를 담고있다고 한다.
그러므로 우리가 원하는 task의 종류에 따라 저 가중치를 조절하여 사용할수 있다.
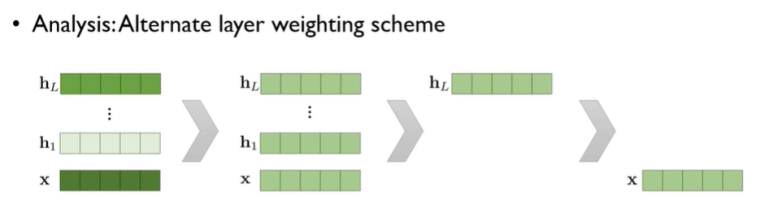
가중합에 따른 성능 비교를 하자면,
task에 맞는 가중합 사용 > 똑같은 가중치로 가중합 사용 > 가장 윗단의 biLM 은닉층 사용 > 기본
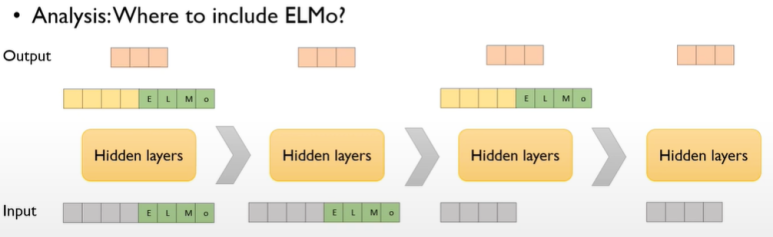
ELMo 결합 방법에 따른 성능 비교
input에 ELMo를 붙이고 output에 다시 ELMo를 붙여줌 > input에 ELMo 붙임 > output에 ELMo 붙임 > 기본
원본 http://jalammar.github.io/illustrated-bert/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French, Japanese, Korean, Persian, Russian 2021 Update: I created this brief and highly accessible video intro to BERT
jalammar.github.io
'Tensorflow 2 NLP(자연어처리) > 사전학습 모델' 카테고리의 다른 글
| GPT-1(Improving languague understanding by Generative Pre-Training)란?+벡터 흐름 하나하나 자세하게 설명 및 논문 리뷰 (2) | 2022.10.10 |
|---|---|
| Transformer이란? ("Attention is all you need") + 벡터 흐름 하나하나 자세히 설명 및 논문 리뷰 (0) | 2022.10.09 |
| [5-4] Attention Mechanism(어텐션 메커니즘)이란? (0) | 2021.11.14 |
| [5-3] 시퀀스-투-시퀀스(Sequence-to-Sequence)란? (0) | 2021.11.13 |
| [5-1] Six challenges(benchmarks) in NLP (0) | 2021.11.13 |