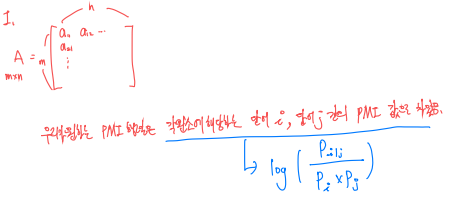
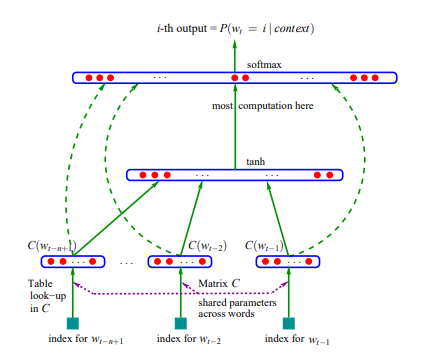
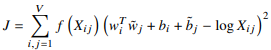단어 임베딩의 품질은 어떠한 기준으로 평가가 이루어 질까? 크게 세 개로 나뉜다. 1. 단어 유사도 평가 (word similarity test) 2. 단어 유추 평가 (word analogy test) 3. 단어 임베딩 시각화 1. 단어 유사도 평가는 일련의 단어 쌍을 미리 구성한 후에 사람이 평가한 점수와 단어 벡터 간 코사인 유사도 사이의 상관관계를 계산해 단어 임베딩의 품질을 평가한다. 이때는 예측 기반 임베딩 기법(Word2Vec, FastText)이 행렬 분해 방법(GloVe,Swivel)들보다 의미적 관계가 잘 녹아있다는 결과가 나온다. (평가 데이터 셋 크가가 충분치 않기는 하지만 다음과 같은 경향을 띤다) 2. 단어 유추 평가는 단어 벡터간 계산을 통해 예를들어 '갑..