
Attention!(주의!) 기법이란 무엇일까?
단순히 말하자면, 다음 결과를 예측하는 작업에서 '이 정보 좀 봐주세요!'라는 의미를 뜻한다.
그리고 그 정보는 인풋으로 들어온 정보들을 현재의 작업에 맞게 정제하여 얻은 추가적인 정보이다.
그리고 이 정보를 참조하여 예측 작업의 '성능' 을 높일 수 있다.
Attention Mechanism은 여러 종류들이 있지만 그 중 한 종류인 (Dot-product Attention)을 소개하겠다.
참고로 Dot-product는 내적이다.
해당 논문
가장 먼저 전반적인 구조를 한 페이지에 시각화해 보았다.
순서대로 따라가 보자.
1. Q, K, V 사전 형태에 대한 이해
Q : 현재 시점 t의 디코더셀의 은닉 상태,
K : 인코더 셀의 모든 은닉상태들의 라벨, key의 개수 : 단어의 개수
V : 각 key에 해당하는 Q에대한 Value(softmax를 거쳐 0과1사이의 값으로 표현됨
=> 즉 현재 디코더에 입력된 단어와 유사한 확률이 Value로 표현됨)
2. 디코더 출력 과정에서, 단순 lstm셀의 은닉층 뿐만 아니라 각 디코더 시점마다 앞서 인코더에 입력된 전체 문장을 다시한번 참조.
=> 인코더에 입력된 단어들 중, 현재 디코더에서 처리되고 있는 단어와 유사한 단어들의 정보를 추가로 제공
=> 다음 단어 예측 능력을 높임
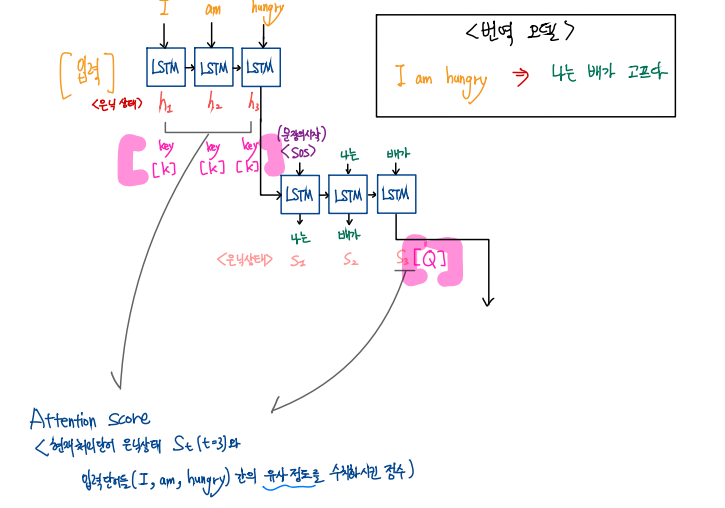
3. 디코더에서 처리하고 있는 단어와 유사한 단어를 인코더에 입력된 단어로부터 찾기 위해 코사인 유사도를 활용함.

=> 내적을 하여 계산
' 디코더 은닉층 하나' vs ' 모든 인코더 은닉층 간 각각' 내적
=> 벡터로 표현(입력 단어의 개수만큼의 차원을 가짐)
=> softmax
=> 확률로 표현됨 : 각 key(단어)에 해당하는 Value(단어 유사 정도)벡터가 된다.
4. 이때 이 정보는 기본 디코더의 은닉층 벡터에 꼬리붙이기 식으로 합쳐짐(concatenate)된다. 하지만 신경망 연산을 한번 더하여서 벡터 차원을 우리가 원하는 형태로 조정
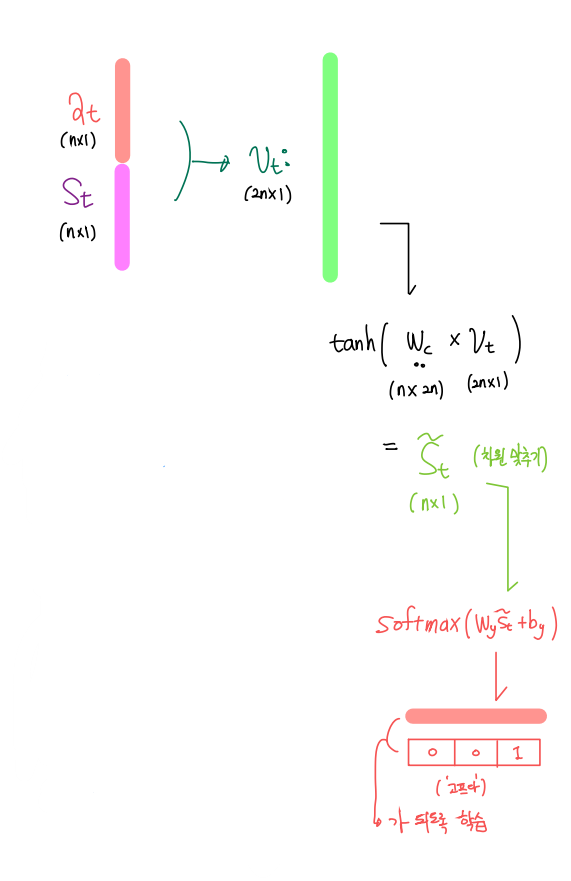
5. 결과를 얻는다.
하지만 여전히 LSTM셀을 이용한다는 단점 때문에 문장이 길 수록 문제가 생기고, 은닉층은 이전 정보들을 함축하는 과정에서 정보손실이 일어난다는 점을 해결하기 힘들었다.
그래서 Transformer에서는 아예 LSTM 셀을 사용하지 않고 오직 attention만을 이용하는 새로운 방향을 제시한다.
'Tensorflow 2 NLP(자연어처리) > 사전학습 모델' 카테고리의 다른 글
| GPT-1(Improving languague understanding by Generative Pre-Training)란?+벡터 흐름 하나하나 자세하게 설명 및 논문 리뷰 (2) | 2022.10.10 |
|---|---|
| Transformer이란? ("Attention is all you need") + 벡터 흐름 하나하나 자세히 설명 및 논문 리뷰 (0) | 2022.10.09 |
| [5-3] 시퀀스-투-시퀀스(Sequence-to-Sequence)란? (0) | 2021.11.13 |
| [5-2] ELMo란? (0) | 2021.11.13 |
| [5-1] Six challenges(benchmarks) in NLP (0) | 2021.11.13 |