Transformer(트랜스포머)의 Attention(어텐션)을 이해하기 위해서 알아야 하는 구조이다.
seq2seq 모델은 함수와 같은 역할을 한다.
입력이 들어오면 출력이 나오고
, 우리는 주어진 입력에 대해 우리가 원하는 출력이 되도록 교사학습(Supervied-learning)을 하면 된다.
함수 내 구조는 어떻게 되어있을까?
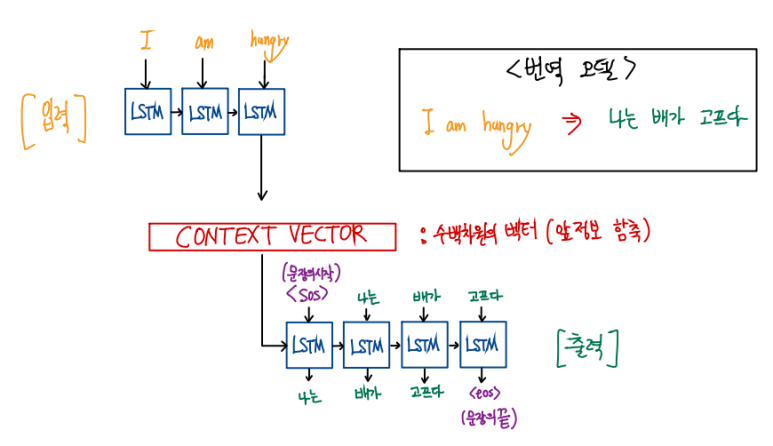
1. 임베딩된 각 단어 'I' , 'am', 'hungry' 를 LSTM(RNN,GRU)에 각각 입력으로 넣어준다.
이 입력 LSTM 층을 '인코더' 라고 한다.
2. 인코더 LSTM 셀의 마지막 시점의 은닉 상태 를 출력 LSTM 층인 '디코더'에 넘겨 주는데
그 넘겨주는 벡터를 'context vector' 라고 한다. (앞의 문장 정보(문맥)를 담았다)
3. 디코더에서 순서에 따른 교사학습(supervised learning)을 시킨다. 물론 출력 활성함수는 softmax이다.
각 softmax의 출력 벡터(3차원) 중 가장 높은 원소의 값이 해당 단어에 해당하는 on-hot 벡터와 같도록 학습시키면 될 것이다.
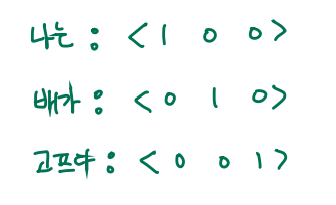
하지만, 이 방법의 문제점은 무엇일까?
1. Vanishing Gradient 발생 (GD를 쓸 것이므로)
2. 한 문장을 하나의 context vector로 만드는 과정에 정보손실이 일어난다.
그래서 이 문제점을 해결하기 위해 'Attention Mechanism'이 생겼고, 이는 'Transformer'의 기반을 이룬다.
'Tensorflow 2 NLP(자연어처리) > 사전학습 모델' 카테고리의 다른 글
| GPT-1(Improving languague understanding by Generative Pre-Training)란?+벡터 흐름 하나하나 자세하게 설명 및 논문 리뷰 (2) | 2022.10.10 |
|---|---|
| Transformer이란? ("Attention is all you need") + 벡터 흐름 하나하나 자세히 설명 및 논문 리뷰 (0) | 2022.10.09 |
| [5-4] Attention Mechanism(어텐션 메커니즘)이란? (0) | 2021.11.14 |
| [5-2] ELMo란? (0) | 2021.11.13 |
| [5-1] Six challenges(benchmarks) in NLP (0) | 2021.11.13 |