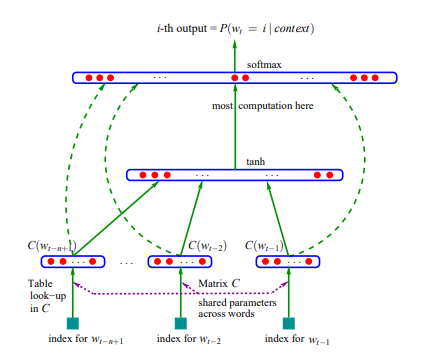
Word2Vec은 2013 구글 연구 팀이 발표했고 가장 널리 쓰이고 있는 단어 임베딩 모델이다. Word2Vec 기법은 두 개의 논문으로 나누어 발표되었다. 논문은 다음과 같다. (Mikolov et al., 2013a) https://arxiv.org/pdf/1301.3781.pdf%C3%AC%E2%80%94%20%C3%AC%E2%80%9E%C5%93 (Mikolov et al., 2013b) https://proceedings.neurips.cc/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf 여기에서 (Mikolov et al., 2013a)에는 Skip-Gram 과 CBOW라는 모델이 제안된다. Skip-Gram은 타..