TF-IDF 는 간단히 표현하자면 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하고(조사 등..),
특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단하여 (주제를 담고 있는 단어일 확률 높으므로) 하나의 값으로 나타내는 것이다. 그래서 TF-IDF값이 높은 단어일 수록 주제를 담고있는 단어라고 말 할 수있다.

1. TF는 특정 문서에서만 쓰인 단어 사용 수이다.
2. DF는 특정 단어가 나타난 문서의 수이다. 그러므로 DF값이 클수록 범용적인 단어라고 할 수 있다.
3. IDF는 N(문서 개수)를 DF로 나누고 log를 취해준다. 그러므로 IDF는 값이 클수록 특이한 단어라고 할 수있다.
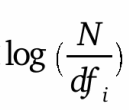
IDF값
4. TF와IDF를 곱함으로써 우리는 단어의 주제함축 정도를 값으로 나타낼 수 있다.
'Tensorflow 2 NLP(자연어처리) > 추가적으로 필요한 개념' 카테고리의 다른 글
| Automatic Differentiation이란 (0) | 2022.10.23 |
|---|---|
| PCA(주성분분석)의 목적함수 증명 (0) | 2021.11.15 |
| [1-6] 도커(Docker)에서 파이썬(python)코드로 작업하기 (0) | 2021.11.12 |
| [1-5] 최대우도법 (0) | 2021.11.12 |
| [1-4] DAN(Deep Averaging Network)란? (+Dropout) (0) | 2021.11.12 |