
제가 지금까지 군생활을 하면서 가장 잘했다고 생각하는 것은
데일 카네기의 인간관계론이라는 책을 읽은 것입니다.
사람이 무엇을 원하는지 확실히 알게 되었기 때문입니다.
사람은 모두 인정받기를 "갈망" 합니다.
좋은 것으로는 부족합니다. "갈망" 합니다.
나의 존재가 인정받기를 원해서 우리는 자신을 다양한 방식으로 표현합니다.
그 중에서 가장 쉽고 효과적인 수단은 "말하기" 입니다.
그래서 사람들은 자신의 이야기를 "들어주는" 사람을 좋아합니다.
나의 존재가 빛날 수 있도록
나를 하늘 높이 들어주는 사람을 좋아하는 감정은 자연스러운 것이니까요.
저의 목표는 친구같은 인공지능을 만드는 것이라고 말해왔습니다.
하지만, 정확히 말하자면 진심을 다해 "들어주는" 인공지능이라는 생각이 듭니다.
이번 포스트는 음성인식분야입니다.
KAIST 정준선교수님의 Session
Self-supervised learning of audio and speech representation을 듣고 정리해봅니다.
목차
# 음성인식 소개
# 음성인식이 어려운 이유
# 모델 INPUT ( MFCC )
음성인식 소개
사람은 여러가지 modality와 감각을 사용해서 주변을 인식한다.
즉, 시각, 청각,후각,촉각, 미각 등 여러가지 Sense를 사용해서 상황을 인지후에 행동을 한다.
그 중에서 많이 쓰는 청각,시각을 살펴보자면
제스쳐,리딩,speach를 통해서 Comunication을 주로 한다.
사람들은 대부분 언어를 사용해서 의사소통을 한다.
언어 중에서도 대화를 통해 Comunication을 한다.
컴퓨터와 사람이 대화를 하기 위해서는 어떻게 해야 할 까?
"음성" 을 사용해 대화할 수 밖에 없다.
음성인식 분야는 2가지 메인 분야가 존재한다.
- ASR ( 음성 인식)
: 무엇을 말하고 있는지 인식하는 것이 목표
그래서 Speach 신호를 받으면, 그에 해당하는 Text를 내뱉는 것
- 화자인식
: 무엇을 말했는지가 아닌 누가 말했는지 인식하는 것
이번 포스트에서는 대부분 ASR에 대해 말할 것이다.
ASR을 요약해보면 Speach를(소리)를 Text로 바꾸는 과정이라 할 수 있다.
시작에 앞서 이 작업이 왜 어려운 일인지를 소개해보려 한다.
음성인식이 어려운 이유
see, sea
hole, whole
right, write 등
이 단어를 음성으로 구분하는 것은 매우 어렵다.
비슷한 소리를 가지고 있는 다른 단어들이 굉장히 많다!
뿐만 아니라, 환경적인 특성에 영향을 많이 받는다.
노이즈, 소리 울림등...
음성인식을 하기 위해서는
굉장이 많은 어휘를 알아야 한다.
일반 성인 어휘는 수천~수만개정도이다.
그래서 성인 수준의 음성 이해를 가능하려면 저정도의 어휘를 인지할 수 있어야 한다.
+ 같은 단어라도 해도
사람이 다른 의미로 이야기 할 수 있다
서울,경상도, 전라도 말투가 다르듯이
사람마다 이 언어를 다르게 구현하기 때문에
같은 사람의 경우에도 감정에 따라
같은 문장이라도 다르게 말하기 때문에 음성 인식이라는 것은 매우 어려운 문제이다!
+ 음성 자체 말고 기계학습(Machine Learning) 측면에서도
음성인식은 Challenge 가 매우 많다
먼저,
Imput 길이가 매우 길다!
nlp를 생각해보면, Imput 길이가 단어의 개수로 사용하는 경우가 많은데
5~10개 수준으로 가능한 정도이다.
하지만, 음성 인식의 경우 음성 input 1초당 최소 16000개, 많으면 44000개가 들어간다;;
그래서 10초의 음성이라 하더라도 input이 수만개가 들어가기 때문에 매우 길다
nlp의 같은 경우도 마찬가지지만,
input이라하면 음성 input이고 output이라면 Word Sequence일텐데
input,output 길이가 sample마다 계속 변한다!
이미지 같은 경우 고정된 크기의 이미지를 반환하지만
음성의 경우 1초짜리가 들어갈 수 도 있고 10초짜리가 들어갈 수도 있다.
Image recognition같은 경우 똑같은 사물에 대해서는 어디에서 이미지를 수집하던지에 영향을 받지 않는다.
하지만, 음성 인식의 경우 데이터가 많은 언어(ex English,Chinese...)가 아닌 이상 특정 언어 data를 얻으려면
그 나라의 사람들에게서부터 얻을 수 밖에 없어 다량의 데이터를 확보하는 것이 힘들다.
## 이런 어려운 문제를 왜 풀어야 하는가?
음성은 우리 주변에서 아주 많이 사용되고 있다.
음성인식 기술이 들어간 제품이 상당히 많다. 하지만 하는 사람이 많지는 않다.
굉장이 여러가지를 할 수 있고 삶을 편안하게 하는 기술이다.
시리, 스마트스피커, 음성인식 기기, 회의록 작성, 화자 인식을 통한 보안인증 같은 기술이
미래의 기술이 아니라 현재의 기술이다!
이미 많이 사용되고 있는 기술이고 시장이 큰 필요한 기술이기에
이러한 어려움에 불구하고도 연구할 필요가 있는 가치있는 분야이다.
음성 인식을 어떻게 하는지 시작하기 전
문제를 정의하고 넘어가자.
음성 인식 : Sound를 Text로 바꿔주는것
input : audio를 feature vector로 -> 좀있다가 설명
output : word/sentence/character level sequence
주로 character 단위 sequence를 사용
소리 X 가 주어졌을 때, 가장 확률이 높은 정답 TEXT를 구하는 것이 목표
기존 Computer vision, NLP 와 마찬가지로 딥러닝을 많이 사용한다.
Deep learning은
output = f(input)인 f를 학습하는 것으로 간단하게 표현 가능한데
audio도 마찬가지로 보면 된다.
모델 INPUT
아까 Input으로 feature vector를 사용한다고 했는데
이 vector는 feature extraction을 통해 얻는다
다른 Deep learning Domain에서는 요즘 사용하지 않는 기술이긴 하다
음성은 특이하게
마이크에서 잡히는 Audio를 바로 집어넣지 않고
다듬어진 feature를 많이 사용하는 중이다.
음성을 모델의 input으로 사용할 수 있는 방법은 여러가지 방법이 있다.
마이크에서 녹음된 정보를 디지털화한 것
Spectrogram, mfcc 등은 사람이 만든 feature이다.
Vision 분야에서는 sift나 Hog라는 이미지 feature 축출 기법을 사용하였다.
요즘에는 feature 를 축출하기 보다는 RGB 이미지(channel을 3개 사용)를 바로 사용한다.
음성 인식에서는 아직
사람이 만든 feature 를 사용하는 쪽이 성능이 더 좋게 나와 아직까지 사용하는 중이다.
물론, 예외도 있다.
FaceBook(Meta) 쪽에서 나온 논문들을 보면 이 사람이 만든 feature 를 사용하기 보다
raw 음성을 바로 사용하는 편이다. ( 하지만 이들 외에 다른곳에서는 사람이 만든 feature를 사용하는 추세이다.)
좋은 feature란 무엇일까?
feature 안에 충분한 정보가 담겨있어야 좋은 feature라고 말할 수 있을 것이다.
그러면 생각해야 할 점이 하나 있는데,
음성 인식을 함에 있어서는 화자 정보를 분리하는 것이 좋다!
=> 음성인식은 무엇을 말하는 지를 알아내는 것이 중요한 것인데 사람마다 가지고 있는 목소리의 특성을 배우게 되면 문제가 생긴다. 이는 불필요한 정보이다.
그래서 Feature의 조건이라 한다면,
Noise와 주변 환경 소리에 대해 강인해야 하고
음성 인식후 내뱉는 output의 차원이 충분히 낮아야 한다.
(input이 16000개인 것에 비해 낮음)
이런 특성을 잘 만족하는 feature가 MFCC라는 것이다.
MFCC(Mel-Frequency Cepstral Coefficient)

1. 마이크에서 아날로그 신호를 디지털 신호로 변경
2. Pre-Emphasis
사람 목소리를 살펴보면, 낮은 주파수대의 음성이 높은 주파수대의 음성보다 에너지가 많다.
하지만, 높은 주파수대에는 정보량이 많다.
이 정보를 잘 얻어내기 위해서 높은 주파수대를 Boosting해줄 필요가 있는데
이때, high-pass fiter(높은 주파수대가 잘 통과되는 필터 -> 낮은 주파수는 잘 통과되지 않음) 를 통해
fiter후에 얻은 정보는 낮은 주파수대의 영향력을 낮춤으로써 높은 주파수대를 더 잘 인식할 수 있게 된다.
3. Sampling and Windowing
마이크에 들어온 압력을 시간에 따라 표현하게 되면
Time(시간)에 따른 Emplitude(압력) 정보를 얻게 될텐데,
사실 어떤 말을 하고 있는지 인식하기 위해서 중요한 것은 Emplitude(진폭)보다는
Frequency(주파수)이다!
그래서 이를 시간당 주파수형태로 얻어내기 위해 Windowing을 진행한다.
Window의 크기는 매우 민감한 hyperparameter이다.
너무 작게 잡으면 의미있는 정보를 온전히 담을 수가 없고
너무 크게 잡으면 여러가지 소리가 뭉쳐져서 해석하기 너무 복잡해진다.
위와 같은 문제들을 고려하여
Window의 크기는 20~40ms 단위로 자른다. ( 보통 25ms로 많이 사용 한다.)
4. Fast Fourier Transform
Fourier Transform 은 신호처리에서 쓰이는 기법인데
Time(시간)에 따른 Emplitude(진폭) 변화를
Frequency(주파수)에 따른 Emplitude(진폭) 변화로 나타낼 수 있게 된다.
(이를 통해 특정 시간 내에 존재하는 다양한 Frequency(주파수)를 가진 신호들 중에
원하는 주파수 영역만 남기고 나머지는 제거한 다음 원래대로 되돌리게 되면
특정 주파수를 없에버리는 필터 역할을 할 수 있다.)
Fast Fourier Transform은 Fourier Transform을 빠르게 하는 알고리즘이다.
5. Mel Filter Bank

사람의 귀는 고주파수 영역보다 저주파수 영역을 더 잘 해석한다.
그래서 모델에서도 이 특성을 반영하여 저주파 성분 영향력 낮추기 및 고주파 성분 영향력 키우기를
Mel Filter Bank에서도 해준다.
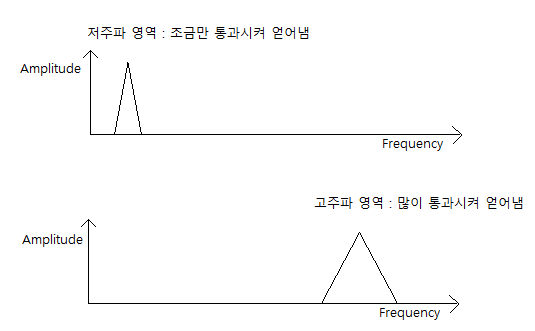
이 삼각형 영역에 해당하는 주파수 영역의 값들을 통과시키는 것이다.
저주파 성분들은 삼각형이 작아서 조금만 통과되고
고주파 성분들은 삼각형이 커서 많이 통과된다.
그리고 이런 삼각형을 N개 만들어서 통과시키면 Mel-Spectrogram이 된다.

6. Discrete Cosine Transform
마지막으로 이미지 압축 기법인 Dicrete Cosine Transform을 통해
Mel-Spectrogram에 존재하던 주파수간의 Correlation을 끊어준다.
이 압축 기법은
Spectrogram을 주파수별로 분리시킨 다음에
해가 되거나 불필요한 주파수를 제거한다.
이를 통해서 각 주파수간에 얽혀있는 Correlation(상관관계)를 끊어낼 수 있다고 한다.
음성에서는 화자에 따라 달라지는 주파수 feature 인 f0 (fundermantal frequency)를 제거하여
feature 하나하나가 화자 독립적이게 된다.
이런 과정을 통해 Mel-Spectrogram에 DCT까지 거치고 나면 비로소 MFCC가 된다.
이때 DCT를 거치고 나서 손실 압축하여 Correlation을 끊고
이후 DCT 역변환을 통해 다시 되돌린 값을 MFCC Coefficients라고 하는데
그때 얻은 각 Time(시간)당 MFCC Coefficients값을
그 Time(시간)의 음성 벡터로 사용한다.
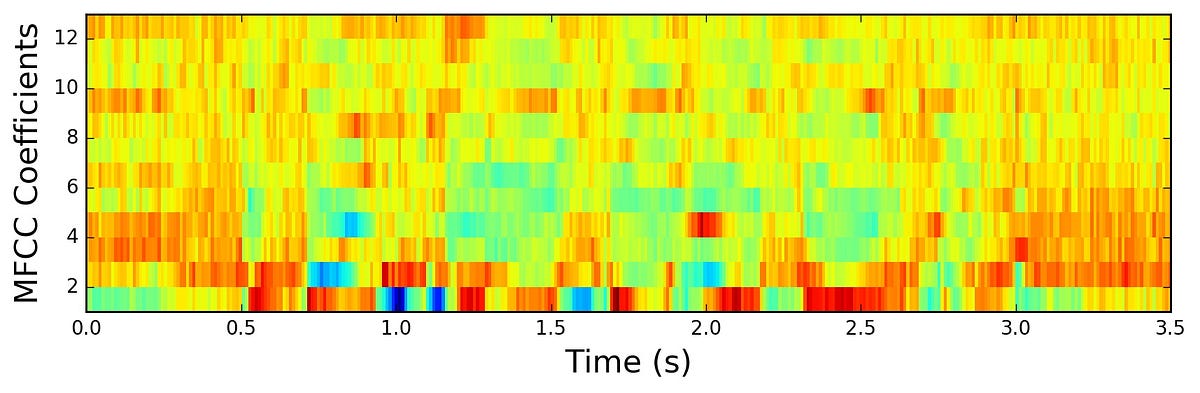
| Mel-Spectrogram vs MFCC
Mel-Spectrogram : 주파수간에 Correlation이 녹아있어서 특정 영역에서 더 잘 동작할 수 있음.
MFCC : 주파수간에 Correlation이 없어서 일반적인 상황에 두루두루 잘 동작함. 즉, 강인하다.
[이미지 압축에 대한 아주 좋은 글]
DCT(Discrete Cosine Transform)와 DFT(Discrete Fourier Transform)
음성 Input에는 최대한 벡터에 정보를 많이 녹아내고 학습 가능하게 만들기 위한 기법들이 사용횐다.
- Dynamic Feature를 추가한다.
: 시간 구간을 적당히 나누어서 그 구간에서 Feature가 어떤 값을 가지고 있는지 뿐만 아니라,
Feature가 어떻게 변화하고 있는지(커지는지 작아지는지 등)에 대한 정보를 Feature에 최대한 녹아낸다.
마지막으로 Mean, Various Normalization을 통해
모델의 input으로 사용하기 적당하게 다듬는다.
다음 포스트에서는 이 INPUT을 넣을 수 있는
다양한 모델과, 기발한 작업들을 소개할 예정입니다.