| From 2021 to 2022
2021
2021 Ramesh et al., “Zero-Shot Text-to-Image Generation (DALL-E),” ICML’21

2021년 1월 5일.
엄청나게 큰 모델과, 엄청나게 큰 Data.
거기에다가 이 둘을 잘 처리할 수 있는 엄청나게 좋은 연산 컴퓨터가 있다면
겁나게 좋은 성능의 이미지 생성 모델을 얻을 수 있다는 것을 발표했다.
( 사실 그 당시 가장 좋은 성능을 뽑아내는 V100 GPU를 가지고도 DALL-E 모델 한개 조차 들어가지 못할 정도로 큰 모델을 사용하였다. 이를 처리하기 위한 다양한 분산 처리 기술들을 활용하였다.(여러개의 GPU에 따로따로 분산학습 시킨다음 합치는 방식) )
DALL-E는
- 12B(120억)개의 parameters를 가진 AR(auto-regressive : 앞선 정보를 바탕으로 다음 정보를 예측) Transformer에다가 250M(2억5천)개의 image-text 쌍 datasets(JFT-300M)
- MS-COCO라는 dataset(image-text pair)를 학습하지 않음에도 불구하고, 이 dataset에 등장하는 text를 전달할 경우 실제 이미지와 매우 유사한 이미지를 생성해냄

- 학습에 사용한 text datasets이 Wikipidea라든지 Web에서 스크랩해온 방대하고 다양한 데이터를 사용했기 때문에 높은 자연어 처리 능력을 지니게 되어 text를 가지고 의도된 image를 생성하는데에 있어 아주 좋은 성능을 보였다.
- 90%의 사람들이 이전 모델의 이미지보다 DALL-E가 생성한 이미지를 더 선호했다.
이런 대단한 모델이 나오게 된 배경이 무엇일까?
1. 뭔가 애매한 성능

앞서 소개한 2019년까지 나왔던 모델의 문제점은
좋아보이긴 하지만
배경이 자연스럽지 못한 방식으로 흐릿하여 불안하고
Object의 위치가 제멋대로거나
이미지 내의 Object의 뒤틀림이라던지 어딘가 부족한 느낌을 지울 수가 없다.
2. Large-scale Models
당시에 Large-scale 모델들이 유행이었다.
- text에서는 GPT-3 (17B(170억) params)
- image에서는 iGPT (6.8B(68억) params)
- audio에서는 Jukebox (5B(50억) params)
parameter 개수를 보면 Billion 단위에 달하는 매우 큰 모델임을 볼 수 있다.
사실 방대한 모델을 학습하는 것은 매우 까다로운데
이미 성공적으로 나온 Large-scale 모델들을 통해 이런 문제가 이미 해소된 상태인 것이다.
이제 학습에 사용할 방대한 image-text만 있으면 된다.
하지만,COCO datasets으로는 부족했다. (학습 데이터 부족은 overfitting을 발생)
그래서 더 큰 datasets과 더 큰 model을 만들었다. (OpenAI같이 거대한 기업이기에 가능한 생각같다.)
하지만, 현존하는 가장 크고 성능이 좋은 모델은
Transformer 기반 모델인데
원래 Transformer는 NLP task를 위해 개발된 모델이어서
sentence나 word같은 discrete한 정보를 처리함에 있어 최적화 되어있다.
(vocabulary에 있는 값이 한정된 정보만 사용해 Token으로 분리 후 Token 그 다음 Token을 예측하는 discrete한 방식)
하지만 이미지는 discrete한 정보가 아니다.
(기존 VAE 같은 경우 가우시안 분포정보를 얻어오다보니 값의 범위가 무한대)
그래서 이미지를 Transformer를 이용해 처리하기 위해
Encoder의 출력에 약간의 형태변환을 시켜준다.
즉, 이미지를 discrete한 vector들(text처럼 한정된 개수(=vocabulary size)의 정보)의 나열로 생각할 수 있도록
VQ-VAE 라는 이미지를 한정된 개수의 vector들(CodeBook)로 표현하는 방식을 선택한다.
이제는 VQ-VAE의 Encoder를 사용해
이미지의 정보가 담긴 discrete한 정보들이 준비되었으므로,
이 정보들을 순차적으로 입력으로 넣었을 때, 그 다음에 해당하는 Token을 적절히 생성할 수 있는(auto-regressive)
학습된 Decoder가 필요하다.
+ auto-regressive하다는 것

이전 모든 단어를 고려해 현재 다음 단어를 뽑아내는 방식
하지만, 길이가 길어지고 개수가 많으면 느려지는데
우리는 Quantisation을 진행하여 이미지를 pixel단위가 아니라
한정된 개수의 feature 벡터 단위( 32x32=1024개의 벡터)로 해석하기 때문에
기존 pixel 단위(겁나 많다)로 이미지를 해석하는 방식보다 훨씬 빠르다!
이제 2개의 모델 구조를 확인해보자.
1. 학습 구조
2. 사용 구조
학습 구조
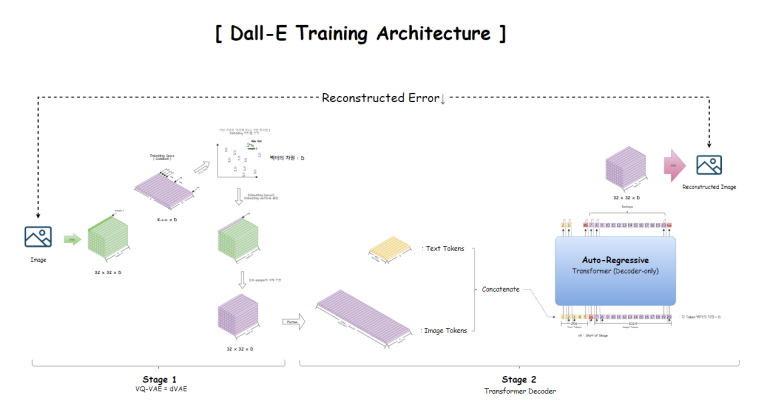
총 2개의 stage로 나뉜다.
첫번째 Stage에서는
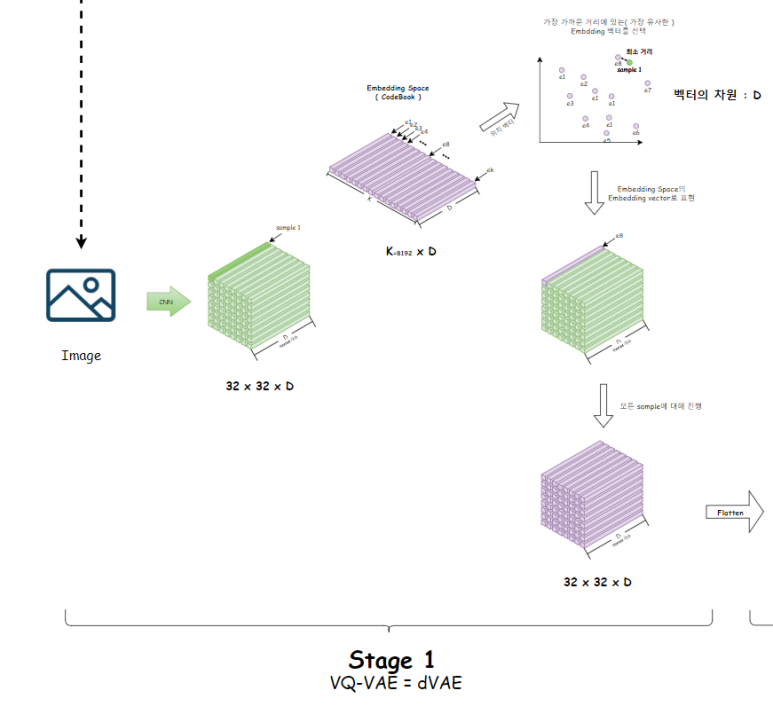
VQ-VAE를 이용한 CodeBook 학습이 이뤄짐과 동시에
CodeBook으로 Encoder의 출력을 근사하는 과정이 이뤄진다.
이때, CodeBook의 K를 8192로 잡고 하는데,
이는 우리가 Text Tokenizing에 사용할 Vocabulary의 크기인 8192와 동일하다.
즉, Text를 Tokenizing하는 흐름과, Image를 Tokenizing하는 흐름을 일치시키기 위해
CodeBook에서 선택가능한 vector의 개수를 8192로 통일한듯 하다.
두번재 Stage에서는
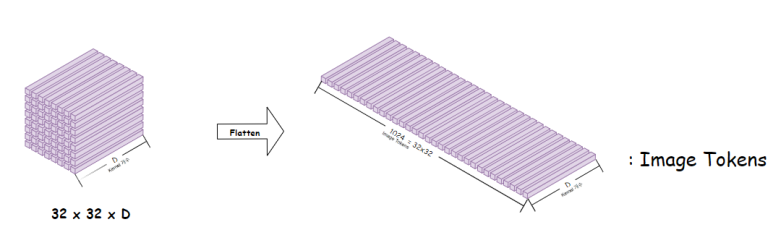
앞서 얻은 CodeBook으로 나타낸 Encoder 출력의 근사 Tensor를
우리는 Image Token으로 사용할 것인데,
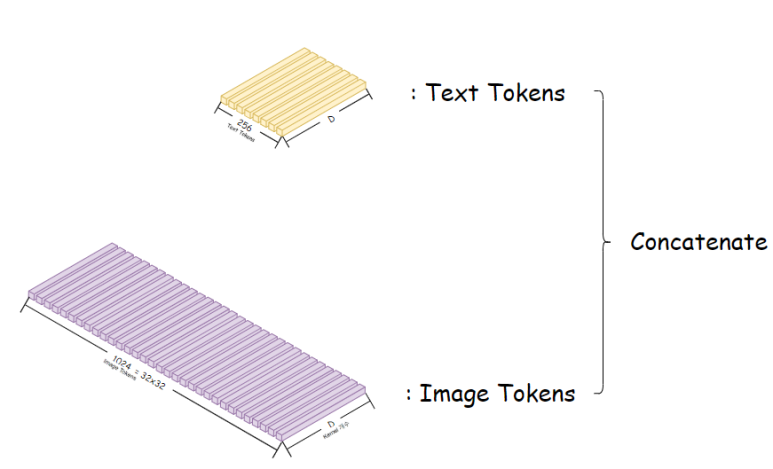
Text와 Image 쌍에 대한 정보를 학습하기 위해
Text Token을 앞에두고 Image Token을 Concatenate(이어붙이기) 한다.
(Text Token은 BPE Tokenizer를 사용해 Tokenizing한다)
(논문 속에서 Text의 최대 길이는 256으로 잡았다)
이제 Transformer의 입력으로 사용하기 위해
- Text Token에는 Positional Embedding을 더해주고,
- Image Token에는 이미지이다 보니 이미지 전반의 정보를 담기 위해 Row정보와 Column 정보를 담은 Embedding을 추가적으로 더해준다.
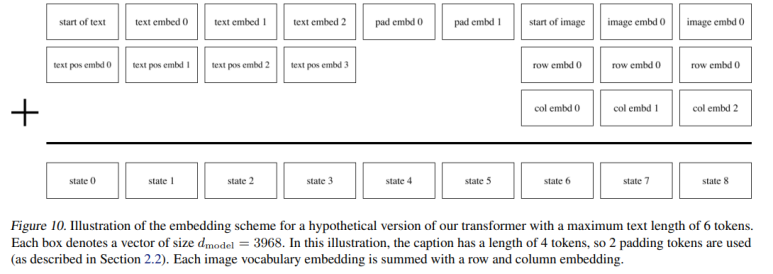
논문에서 설명하는 Transformer 입력 형태 예시
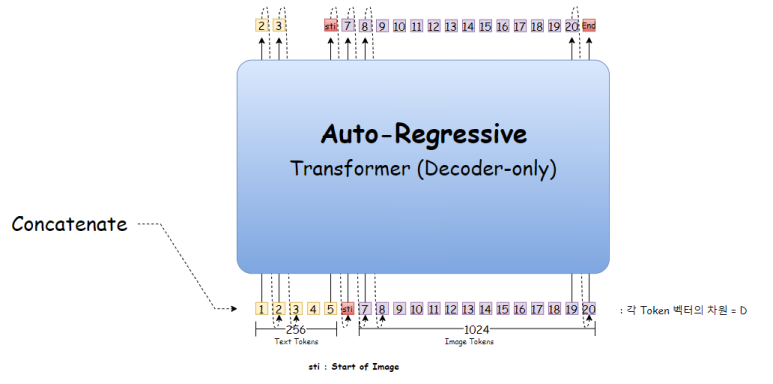
이 이어붙인 것을 Decoder로만 이뤄진 Transformer에 태우는데
Auto-regressive하게 학습을 진행한다.
(Text의 마지막 oken이 예측하는 Token은 Image의 시작을 알리는 Start of image(sti)라는 special token을 사용한다)
( 그리고 Decoder만 사용하다보니 Attention mask가 필요한데, Text의 경우 기본 mask를 쓰는 반면, Image같은 경우 성능 향상을 위해 다양한 형태의 mask를 사용한다)
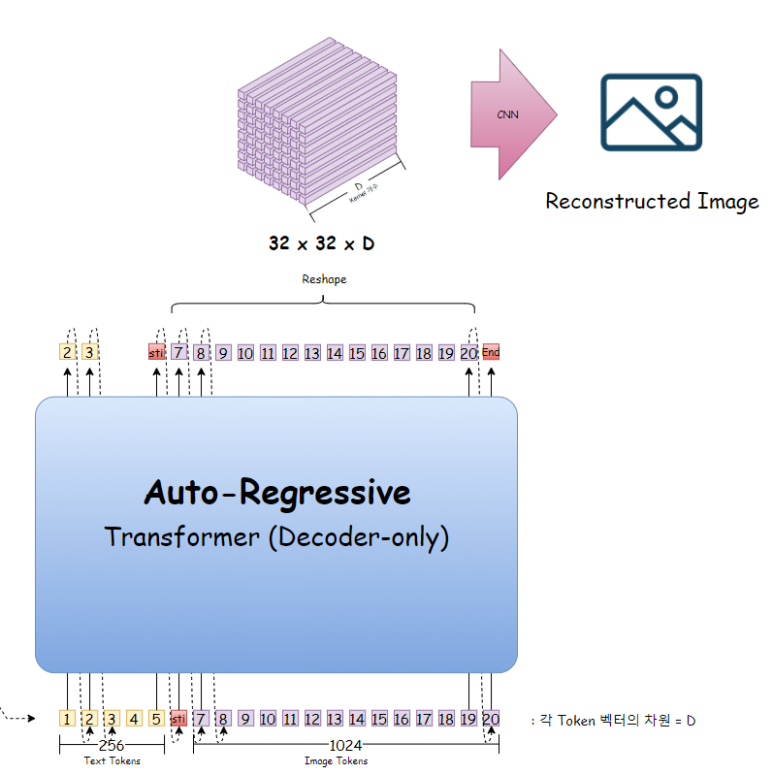
이제 Transformer의 출력에 해당하는 Image Token들을 다시 원래 Tensor형태로 reshape한다음에
CNN을 가지고 다시 원래 이미지를 복원한다.
이 복원한 이미지가, 원래의 이미지가 되도록 학습이 진행된다.
사용 구조
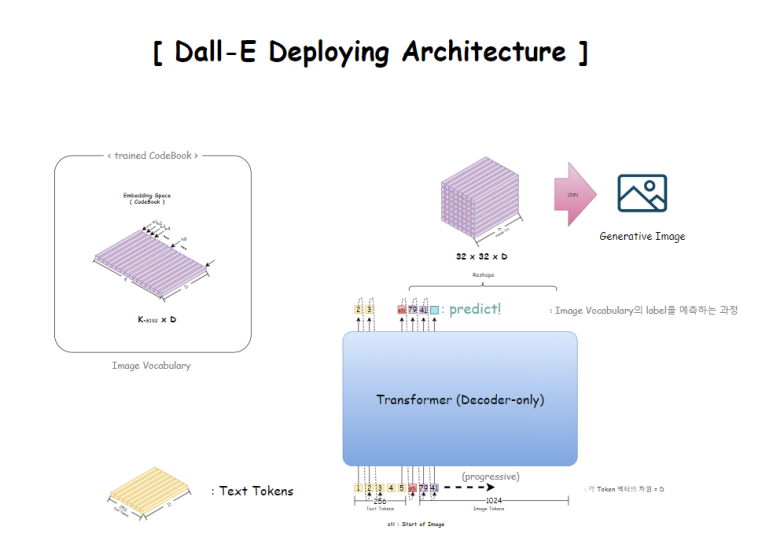
학습이 완료되면, 아래 3가지를 얻을 수 있다.
1. 학습된 CodeBook
2. 학습된 Transformer
3. 학습된 Image 생성 CNN
이제 우리가 생성하고자 하는는 Image의 Text설명을 Tokenizing하여
Transformer의 입력으로 집어넣으면,
Image Token을 Auto-regressive하게 하나하나씩 예측해나간다.
즉, 앞선 Text 입력과 Image Token을 보고
그 다음에 올 확률이 가장 높은 Image Token을 예측하는 것이다.
( 정확히 말하자면, label을 예측하고 이후 그 label에 해당하는 vector를 Image Vocabulary에서 찾아서 바꾼다)
예측이 완료되면,
출력에 해당하는 Image Token들을 다시
Tensor형태로 되돌리고,
이를 학습된 Image 생성 CNN을 통해 이미지를 생성해낸다!
성능

이제 성능을 확인해보자.
Dall-E에서는 보다 훌륭한 이미지 생성을 위해
이미지 생성을 한번에 끝내는 것이 아니라, 하나의 text에 대해 많은 이미지를 생성해놓고
그중에서 가장 좋은 품질의 이미지를 선택하는 방법을 선택했다.
그렇다면, 좋은 품질의 이미지를 선택할 수 있는 모델이 필요했는데
이미 OpenAI에서는 2021년에 CLIP이라는 이미지-Text matching 모델을 선보였다.
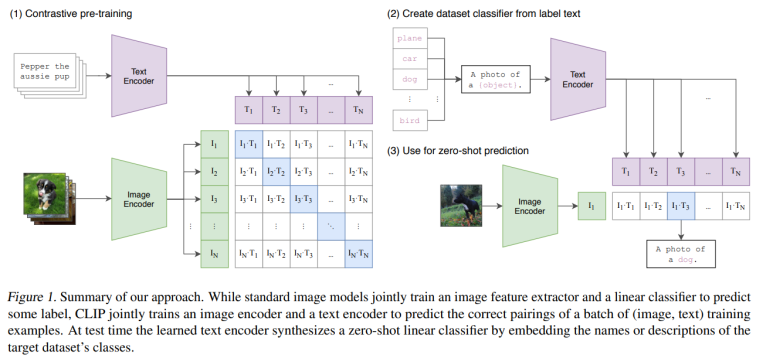
CLIP의 구조는 매우 간단하다.
이미지-Text 쌍 데이터가 있을 텐데
각각 Transformer 기반의 Encoder를 거친다.
후에, 특정 이미지에 대한 Encoder의 출력값이
그 이미지에 해당하는 Text의 Encoder 출력값과 가장 유사해야하는 방향으로 학습을 진행한다.
( 이 과정을 위의 행렬로써 나타낼 수 있다. 저 파란색 영역이 가장 큰 값을 가져야 함을 쉽게 이해할 수 있다)
(이미지에 해당하는 Encoder는 ViT라는 이미지를 위한 transformer(Vision Transformer)를 사용했다.)
학습이 끝난 후에,
하나의 이미지를 Encoder에 넣고 얻어낸 출력값에 해당하는 Text를 찾고 싶다면,
여러가지의 Text를 Text Encoder에 넣은 다음 얻어낸 출력값 중에
이미지 Encoder 출력값과 가장 유사한 Text Encoder 출력값을 찾아내면 될 것이다!
이는 한개의 query에 대한 여러개의 Key의 attention 값이라고 이해할 수 있고,
이는 하나의 이미지에 대해 "정답 Text가 될 수 있는 가능성(확률)"이라고 여길 수 있다!
이제는 이 모델을 활용해서
Dall-E의 출력 이미지들에 정답 Text과 얼마나 유사한지에 대한 정도에 따른 점수를 부여할 수 있을텐데
그 점수중에 상위 K개의 이미지들을 뽑아올 수 있게 된다! ( 저 위에서는 K=1 로 설정해서 가장 우수한 이미지 1개를 얻어낸것이다)

이제, 이전에 SOTA를 찍던 모델의 이미지를 보면서 성능비교를 해보면
확실히 압도적인 성능을 뽑아내고 잇는 것을 확인할 수 있다!

그리고, Dall-E가 이미지 생성 분야의 특이점이라고 할 만한 모델인 이유는
한번도 보지 못한, 실제로는 존재하지 않는 설명의 이미지들을
고차원의 Text 의미를 이해하고 잘 조합하여
정말 그럴듯하게 생성해낸다는 점이다.
위의 결과를 처음 본 연구원들은 어떤 느낌이었을지 상상해본다면
정말 가슴이 벅차올랐을것 같다.
2022
2022 Villegas et al., “Phenaki: Variable Length Video Generation from Open Domain Textual Descriptions,”(Submitted to ICLR’23)
학술대회 당시에는 올해였던...2022년 (벌써 한달이 넘게 지나버렸다)
Google에서 진행한것으로 보이는 연구가 하나 있다.
Phenaki 라는 이미지 생성을 넘어 "비디오" 생성까지 분야를 넓혔다.
즉, 생성되는 이미지가 시간별로 달라지는 것이다!



- 첫번쨰 동영상 Prompts used:
A photorealistic teddy bear is swimming in the ocean at San Francisco
The teddy bear goes under water
The teddy bear keeps swimming under the water with colorful fishes
A panda bear is swimming under water
- 두번째 동영상 Prompts used:
A teddy bear diving in the ocean
A teddy bear emerges from the water
A teddy bear walks on the beach
Camera zooms out to the teddy bear in the campfire by the beach
- 세번쨰 동영상 Prompts used:
Side view of an astronaut is walking through a puddle on mars
The astronaut is dancing on mars
The astronaut walks his dog on mars
The astronaut and his dog watch fireworks
VQGAN vs MaskGIT
Phenaki의 구조는 사실 이미지 생성 과정에
시간성을 부여해준 것 뿐이여서
단순히 시간에 따른 생성 이미지가 우리가 원하는 이미지가 되도록 학습시키면 끝이다.
그때 MaskGIT이라는 이미지 생성 모델을 썼는데
이전에 소개한 VQ-VAE와 아이디어가 동일한 VQGAN 의 단점을 넘어섰다.
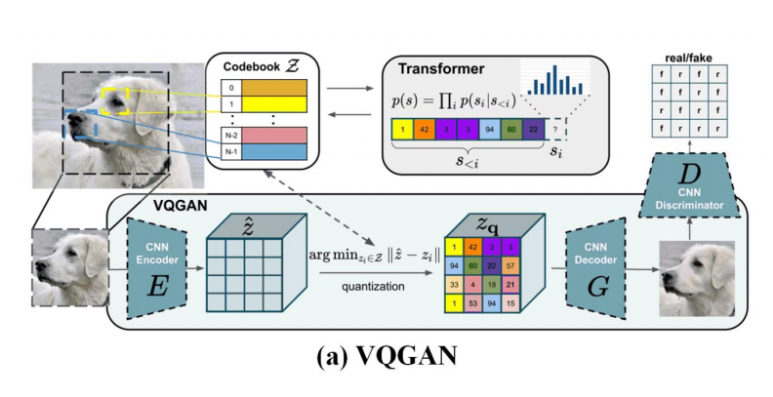
VQGAN은 VQ-VAE(dVAE)의 아이디어인 CodeBook을 사용해
Discrete한 개수의 Image Vocabulary를 만들어서 Transformer의 입력으로 사용하자는 생각과 동일하다.
다른점이라면, 생성된 이미지에 Discriminator를 추가함으로 인한
각 CodeBook에 따른 True-False를 판단시켜
적대적 학습이 가능하게 구성하였다는 점이다.
VQGAN의 단점이라면,
CodeBook을 줄인다고 줄였지만, 성능이 괜찮게 나오는 선에서
최소의 CodeBook개수도 너무 많은 편이라는 점이다.
이렇게 CodeBook 개수가 많아지면, 연산량이 증가하게 되고 처리 속도 저하로 이어진다.
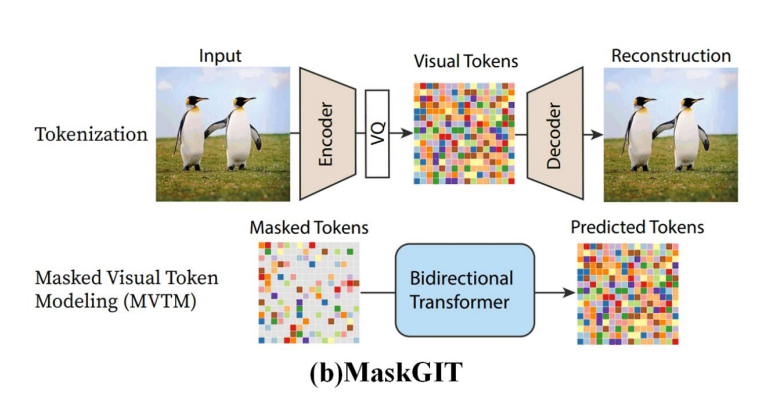
이를 해결하기 위해 BERT에서도 사용되는 아이디어인 Mask씌운 부분을 복원해내는 과정을 통해
이미지를 생성하는 모델인 MaskGIT을 사용했다.
Mask는 랜덤으로 씌어지기 때문에
순서대로 모든 라인을 훑을 필요(Auto-regressive)가 없어 연산량이 확 줄어들고
그 자리에서 즉시 이미지 생성이 가능하게 되었다!
마무리
지금까지 2016년부터 2022년까지 Generative model의 역사를 거슬러 올라왔습니다.
근데 빼먹은게 하나 있습니다.
바로 Diffusion model 입니다!
이전에는 GAN모델이 이미지 생성 분야를 휩쓸엇는데
이제 Diffusion model이라는 새로운 모델이 나왔습니다.
분자가 퍼졌던 것을 다시 역순으로 되돌리는 형태의 이 모델은
현재 생성모델로써 우수한 성능을 보이고 있습니다.
이 Diffusion model에 대해 다음 포스트인
How A Diffusion Model Works in Text-to-Image Translation( KAIST 주재걸 교수님 ) 에서
자세하게 다뤄보겠습니다.
마지막으로, 생성모델이란 무엇일까요?

우리 세상의 구조를 이해하고 있는 모델이라고 말할 수 있을것 같습니다.