
StackGAN 이라는 이름을 보건데,
GAN을 stack(쌓다)하였음을 유추할 수 있다.
StackGAN은 text condition을 줌으로써 이미지 생성을 했을 때,
성능이 그리 좋지 못한것을 보고 더 명확하고, 고화질의 이미지를 생성하기 위해
다음과 같은 아이디어를 제시했다.
2개의 GAN을 사용하는 것이다.
첫번째 GAN은 대략적인 형태, 사물과 배경의 색깔등에 중점을 둔 스케치 이미지 생성을 담당한다.
두번째 GAN은 앞서 생성한 스케치 이미지의 오류를 고치면서 디테일을 추가하고, 더 고화질의 이미지를 최종적으로 생성한다.
이렇게 세부 역할 분담을 하면,
어려운 문제가 그나마 쉬운 여러 문제로 나뉘게 되고
덕분에 더 좋은 성능의 이미지를 얻을 수 있다.
목차
1. 전반적인 도식도
2. 개요
3. Conditioning Augmentation
3.1. 기존 text 임베딩의 문제점
- latent data manifold의 discontiunity란?3.2. 이를 보완하기 위한 Conditioning Augmentation 과정
4. Stage-I GAN
4.1. 간단 구조 도식 및 요약
4.2. 자세한 구조
4.3. 목적함수 설명
- text embdding의 생성 방식
- 목적함수 설명
5. Stage-II GAN
5.1. 간단 구조 도식 및 요약
5.2. 자세한 구조
5.3. 목적함수 설명
6. StackGAN++
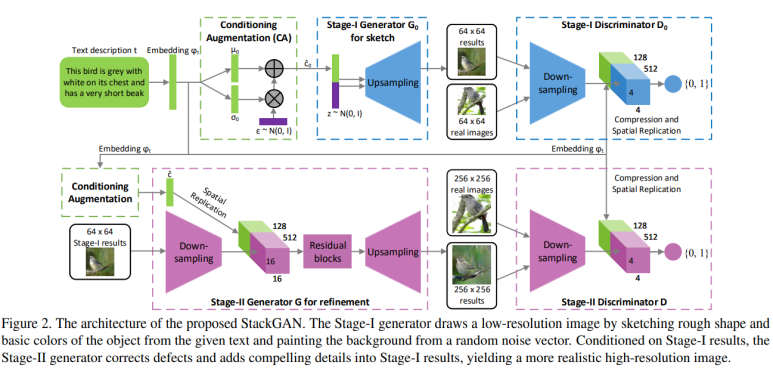
전반적인 도식도를 보면 위와 같다.
복잡해 보이기도 한다.
우리도 이 복잡한 것을 이해하기위해
하나하나 분해해 쉬운 문제로 만들어 진행해본다.

위의 내용은 GAN 글에서 아주 자세하게 이해할 수 있다.
Conditioning Augmentation


[26] Generative adversarial text-to-image synthesis. In ICML, 2016. : GAN에 text label를 같이 전달해서 text에 대한 image를 생성하도록 시도한 첫번째 논문
[27] Learning what and where to draw. In NIPS, 2016. : GAN에 text label을 같이 전달해서 text에 대한 이미지를 생성하는 것은 좋은데, 이미지 내에 사물이 무엇이고(What) 어디에 위치하는지(Where)에 대한 정보를 추가적으로 넣어줘서 보다 정확한 이미지 생성을 시도한 논문
Conditioning Augmentation은 아래와 같은 2가지로 나눠서 정리할 것이다.
1. 기존 text 임베딩의 문제점
- latent data manifold의 discontiunity란?
2. 이를 보완하기 위한 Conditioning Augmentation 과정
기존 text 임베딩의 문제점
input으로 이미지에 대한 text 설명을 같이 넣어주는데
이 text는 encoder를 통과해서 text embeddig이 된다.
하지만, 이 임베딩의 품질에 문제가 있다.
그 이유는
보통의 text 임베딩 과정에서
text는 encoder(신경망)을 거쳐 높은 차원(100차원 이상)의 벡터로 변환되는데
사용하는 text data의 개수는 적은 반면에 임베딩 차원이 크게 되면
latent data manifold에서 불연속성(discontinuity)를 초래할 가능성이 있다.
이 불연속성은 이미지 생성 Generator를 학습하는데에 악영향을 끼친다.
latent data manifold에서 불연속성(discontinuity)가 어떤 뜻을 의미하는지 자세하게 풀어놓은 글을 못찾아서
자세하게 설명해보겠다.
latent data manifold의 discontiunity란?
아주 간단하게 말하면 "차원의 저주" 이다.
차원의 저주란?
차원이 높을수록 고차원의 많은 정보를 담을 수 있다.
그래서 모델 학습 측면에서,
차원이 높은 데이터를 입력으로 넣어주면 성능이 높아지기도 한다.
다만, 충분히 많은 데이터가 존재한다는 전제가 있다.
데이터가 충분치 않다면
고차원의 정보는 그저 너무 많은 측면을 고려하는 "쓸데없이 복잡한" 정보 일 뿐이다.
3명의 사람을 구별하기 위해
각 사람의 얼굴만 대충 기억하면 되지, 굳이 그 사람의 인생사를 알 필요는 없다.
10000명의 사람을 구별해야 한다면
얼굴이 비슷한 사람이 있을 수 있으므로, 이때 세부적인 특성까지 고려하면 된다.
이렇게, 차원을 높이는 것은 쓸모가 있지만,
데이터가 충분치 않을 때 좋은 성능을 내지 못하는 경우를 차원의 저주라고 말한다.
사용하는 text data의 개수는 적은 반면에 임베딩 차원이 크게 되면
latent data manifold에서 불연속성(discontinuity)를 초래할 가능성이 있다.
이제는 좀더 자세하게 상황에 맞게 이해해보자.
가장 먼저 data manifold란 무엇인지 알아야 할 것이다.
정리하자면,
저차원의 데이터를 고차원으로 표현하였을 때
고차원 상에서 데이터간의 특성 관계(위치 관계x)를 가장 잘 표현할 수 있는 다차원 곡면이라고 할 수 있다.
그런데, manifold만을 아는 것 만으로는 부족하다.
임베딩에 대해서도 알아야 한다.
임베딩이란 데이터를 벡터화 시키는 것이다.
이 벡터화를 왜 시키고, 벡터화된 임베딩은 과연 어떤 의미를 지닐까?
임베딩의 목적은 " 벡터에 실제 의미를 담는다 " 이다.
의미를 담는 방식을 한 문장으로 말하면 " 비슷한 것은 가까이, 다른 것은 멀리 " 이다.
비슷한 성격을 가지는 데이터는 임베딩 과정을 거치면 서로 비슷한 공간상에 위치하고,
다른 성격을 가지는 데이터는 서로 멀리 떨어진 공간상에 위치하도록 한다.
이렇게 잘 위치시킨 고차원상의 임베딩 위치 벡터 data로 부터
우리는 manifold를 얻어낼 수 있다.
이 manifold는 임베딩이 제 역할을 잘 할 수 있는 공간이다.
즉, 다차원 공간에서 각 데이터가 성격에 따라 유의미한 변화를 할 수 있는 공간이다.
이 manifold 자체는 각 데이터의 "local linear patch"들이 다닥다닥 이어붙어서
연속적인 곡면형태를 띄어야 하는데
데이터가 적을 경우, 이 데이터를 가지고서는 연속적이지 못하고 부분부분이 끊기는
질 낮은 manifold를 따라갈 수 밖에 없기 때문에,
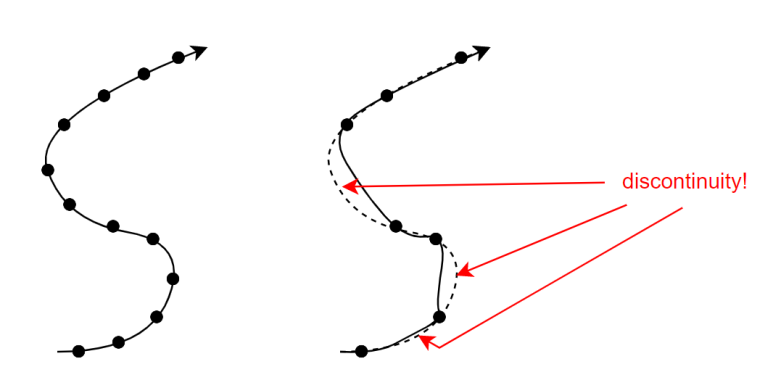
이 임베딩 벡터는
다차원 공간 상에서 각 text간의 의미 관계를 제대로 처리하기에는 부족한 능력을 지닌 것이다.
요약하자면,
저 고차원 영역은 적은 데이터들에게는 과분한 공간인 것이다.
이를 보완하기 위한 Conditioning Augmentation 과정

Augmentation이라는 이름에서 알 수 있다 싶이
데이터 증강Augmentation의 과정이다.
앞서 데이터 부족으로 인한 임베딩의 성능 하락 문제를 완화mitigate하기 위해
이전에는 text 임베딩만을 추가적인 영향을 끼치는 입력(conditioning variable)으로 넣어주었지만,
StackGAN에서는
한번만에 얻은 text 임베딩을 사용하는 것이 아니라

text 임베딩의 평균 µ(ϕt)과 공분산 Σ(ϕt) 을 만족하는 가우시안 분포Gaussian distribution에서
text 임베딩을 샘플링(뽑기) 한다.
이런 뽑기를 하는 이유는
1. 확률적인 뽑기를 진행하여 더 많은 데이터가 고려된 값을 얻을 수 잇고
2. 작은 변화들에 대해 강인하게 하기 위함이다.
추가적으로,
1. manifold의 불연속한 부분을 줄여 더 스무스하게 만들고
2. 과적합(overfitting)을 막기 위해
규제regularization를 학습 목적함수에 넣어준다.

KL divergence에 대해 집고 넘어가자면,
두 확률 분포간의 차이를 의미한다.
임베딩 뽑기 확률 분포와, 표준 정규분포의 확률 분포 간의 차이를
목적함수에 넣으면, 이 차이를 줄여나가는 방향으로 학습하게 될 터인데
이는 임베딩 뽑기 확률 분포에 노이즈를 추가하는 것과 동일한 것으로 생각할 수 있다.
이는 하나의 텍스트에 대해 다양한 포즈와 형태의 이미지가 나올 수 있는 경우를 고려하여
텍스트에 조금 더 불확실의 여지를 추가한 것이다.(텍스트 임베딩의 영향력을 조금 낮추는 기능을 함)

이제 이를 그림으로 보면 위와 같다.
임베딩을 먼저 뽑는데
우리는
1. 임베딩의 평균과 임베딩의 공분산을 만족하는 가우시안 분포에서 뽑기를 하는데
2. 노이즈가 추가된 뽑기여야 한다
라는 위 두가지를 만족하는 뽑기를 하기위해
방식은 다르지만 동일한 역할을 해내는 작업을 수행한다.
1. 임베딩의 공분산에 노이즈를 곱한다음 이를
2. 임베딩의 평균과 더한다
이러면 Conditioning Augmentation이 끝난다.
Stage-I GAN
1. 간단 구조 도식 및 요약
2. 자세한 구조
3. 목적함수 설명
- text embdding의 생성 방식
- 목적함수 설명
간단 구조 도식 및 요약
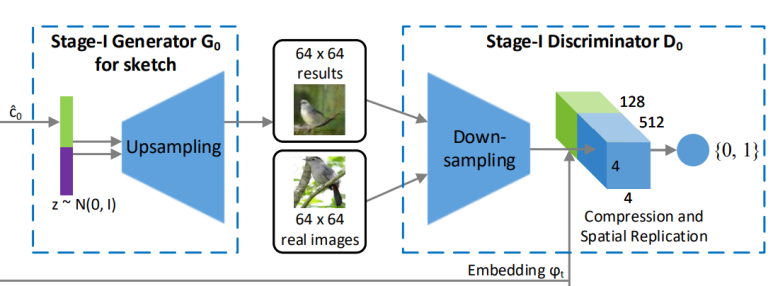
StackGAN에서는 2개의 GAN을 거친다고 앞서 말했다.
첫번째 GAN은 대략적인 형태, 사물과 배경의 색깔등에 중점을 둔 스케치 이미지 생성을 담당한다.
두번째 GAN은 앞서 생성한 스케치 이미지의 오류를 고치면서 디테일을 추가하고, 더 고화질의 이미지를 최종적으로 생성한다.
대략적인 형태, 사물과 배경의 색깔등에 중점을 둔 스케치 이미지 생성은 어떤 과정으로 진행될까?
자세한 구조


1. 앞선 Conditioning Augmentation을 통해 얻은 c^와 랜덤노이즈 벡터 z를 서로 이어붙인다. (concatenate)
2. 이어붙인 벡터를 2D 행렬형태로 형태를 바꿔준다음
3. Upsampling(nearest-neighbor upsampling : 복사해서 키우는 방식 )이라는 확대 기법을 이용해
64x64짜리 이미지를 만든다. ( 스케치 이미지이다 )
4. 여기서 우리는 텍스트의 정보를 추가적으로 이미지에 전달하기 위해 사이즈를 줄일 것이다.
이미지를 Downsampling(정방향 CNN)이라는 축소기법을 이용해 4x4 까지 줄인다.

5. 4x4 짜리 이미지는 CNN을 이용해 만들었고, kernerl 개수가 512개여서
4x4x512 형태의 3차원 Tensor가 생성된다.
6. 여기에 Text임베딩은 차원이128인 벡터인데, 이를 16개를 복사한다음 차원을 확장해
4x4x128 형태의 3차원 Tensor를 만든다.
( Text임베딩을 16개 복사한다음에, 전면이 4x4형태가 되도록 형태를 다시 잡아준 것이다. )
7. 이 둘을 이어붙인다. (concatenate)
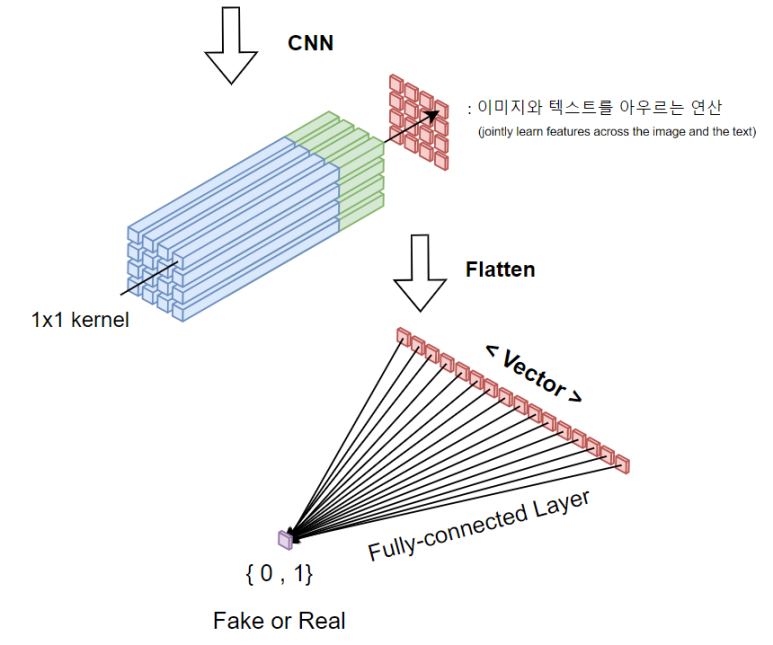
8. kernel 크기가 1x1 인 CNN을 진행하여 이미지와 텍스트를 아우르는 연산을 수행한다.
9. 출력 node개수가 1개인 Fully connected Layer를 통과시켜서, 0 Fake 또는 1 Real를 판단한다.
목적함수 설명

한번에 고화질의 이미지를 만드는 것보다,
역할을 세부적으로 분리해서
대강 이미지를 생성한 다음에 => 디테일을 잡아나가는 방식을 선택했다.
일단, 우리는 GAN을 이용해 우리가 "의도한" 이미지를 생성하기 위해
text라는 condition을 제공했다.
text로부터 어떤 방식을 통해 condition을 얻었을까?
1. text embdding의 생성 방식
2. 목적함수 설명
text embdding의 생성 방식

[25] 논문Learning Deep Representations of Fine-grained Visual Descriptions 에서
텍스트를 인코딩 하는 방법은 두 가지가 있다.
Char-CNN-RNN과 Word-CNN-RNN이다.
방법은 아주 간단하다.
일단, 기본이 되는 Char-CNN 부터 보자면,
이름이 뜻하는 것은
1. Character 단위로 쪼갠다음, 2. CNN을 거치는 인코더이다.
Text를 CNN으로 읽어오는 작업은 많이 사용하는 방식이다.
들어가기에 앞서, 주의할 점이 있다.
보통 우리는 text 임베딩을 할 때,
text를 먼저 Tokenizer를 이용해 Tokenizing을 하고
각 Token을 임베딩을 시킨 후에
모든 Token의 평균을 내던지 등, 특수한 계산을 통해 문장의 임베딩을 얻어낸다.
하지만, 이 경우 임베딩의 품질이 Tokenizer에 큰 영향을 받게 된다.
그래서 논문에서는 기본적으로 Word 단위∈Token단위로 text를 분리하지 않고,
character단위로 text를 분리했다. / 추가적으로도 Word단위로도 분리한 방법도 소개했는데 이것이 Word-CNN-RNN인 것이다.

1. text를 character 단위로 분리한다.
2. 각 character를 kernel(filter) 크기만큼 참조하면서 오른쪽으로 슬라이싱 할 것인다.
3. 원하는 크기까지 다다르면, Flatten해서 벡터를 뽑아낸다.
4. 최종적으로, 이 벡터에 FC(Fully connected) layer를 거쳐서 우리가 원하는 크기의 text 벡터를 얻는다.
하지만, CNN을 이용한 text 처리의 치명적인 단점은
Kernel 크기만큼 character들을 참조하여 처리할 것인데
이는 text의 부분부분만 읽어와서 text 전반적인 흐름정보를 담기 힘들다.
그렇다고 CNN의 엄청난 장점인 1. 빠른 속도 2. 긴 text에 대해서도 준수한 계산량을 놓치는 것은 아쉽다.
그래서 이 단점을 보완하기 위해
약간 변형을 시킨다음, 그 위에 2층의 RNN layer를 추가한다.
이렇게 구성한 이유는
CNN의 빠른 처리속도를 사용함과 동시에, RNN을 통한 text의 sequence 정보를 모두 담기 위해서이다.
+ 좋은 CNN 글
Char-CNN-RNN
이름이 뜻하는 것은
1. Character 단위로 쪼갠다음, 2. CNN을 거치고, 3. 최종적으로 RNN을 거치는 인코더이다.
앞서 우리는 하나의 kernel에 대한 vector를 얻어올 때,
sequence의 끝까지 모두 슬라이싱을 거쳤다.
하지만, RNN의 input 벡터를 만들기 위해서는
시간 단위마다 잘라줄 필요가 있다.
그래서 아래와 같이, seqeunce 방향이 아니라 시간 차원 방향으로 잘라서 벡터를 만든다.

그렇다면, 각 step마다 kernel개수만큼의 차원을 가지는 벡터들이 생겨날 것이다.

이 벡터를 이제 RNN에 집어넣는다.
그리고 마지막 hidden vector들의 평균을 text vector로 사용한다!
+ Word-CNN과 Word-CNN-RNN은
text의 분리 단위가 character가 아니라 Word단위로 나누는 것만 다르고
나머지는 위와 같다.
목적함수 설명

이 목적함수는 GAN 을 알고 있다면, 바로 이해 가능하다.
기존 GAN은 아무 condition 없이 이미지를 바로 집어넣은 반면,
StackGAN에서는 text embedding이란 condition을 주었기 때문에
괄호 안 실제 이미지 I0옆에 ϕt가 추가된 것을 볼 수 있고,
Generater의 괄호 안에는 Conditioning Augmentation을 통해 얻은 c^0까지 들어감을 확인 할 수 있다.
추가적으로, Generator 관점에서 학습할 때 ( 위조범 입장에서 경찰을 속여야함 )
앞서 소개한 규제가 추가적으로 들어있음을 볼 수 있다.
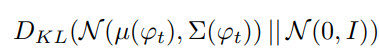
다른점이라면, 앞에 λ(람다) 가 붙어서 두개의 항의 균형을 맞추는 hyperparameter가 추가된 것을 볼 수 있다.
( 논문에서는 모든 경우에 대해 λ=1로 놓고 학습을 진행함 )

마지막으로 이런부분이 있다.
µ0(ϕt) 와 Σ0(ϕt)이 신경망에서 jointly 잘 학습되도록, reparameterization trick을 사용한다고 한다.
이게 무슨말이냐면, µ0(ϕt)와 Σ0(ϕt)는
text embedding에 신경망을 거친 출력이 µ0(ϕt)와 Σ0(ϕt)이 되도록하는 2개의 신경망을 학습시켜
얻어내기 때문에
parameter 2개가 jointly(동시에) 잘 학습되기 위한 [13]논문에 나오는 trick을 사용했다는 것이다.
[13] Auto-encoding variational bayes. In ICLR, 2014. : VAE라고 불리는 유명한 논문
Stage-II GAN
1. 간단 구조 도식 및 요약
2. 자세한 구조
3. 목적함수 설명
간단 구조 도식 및 요약


Stage-I GAN을 통해 얻은 저화질의 이미지는 대체로 물체의 생생함이 부족하고, 형태가 찌그러져있다.
입력 text의 디테일들이 첫번째 이미지 생성 단계에서 빠졌기 때문이다.
Stage-II GAN는 Stage-I GAN에서 얻은 이미지를 기반해 고화질의 이미지로 만든다.
앞서, text의 디테일을 담지 못햇으므로,
다시한번 Conditioning Qugmentation을 통해 얻은 text embedding을 넣어준다.
자세한 구조

과정을 보면,
1. 앞서 얻은 Stage-I GAN 을 Down-sampling(CNN) 거친다음
Conditioning Augmenation을 통해 얻은 text embedding을과 앞서 동일한 방식으로 concatenate한다.
( Conditioning Augmenation에서 평균과 공분산을 얻기 위해 사용하는 신경망은 Stage-I GAN에서 쓰던 것이 아니라 새 것으로 사용한다 )
2. concatenate한 Tensor를 Residual blocks에 집어넣는다.
이 block은 Resnet으로 구성된 블록이다.
( 128 x128 이미지를 생성하는데에는 2개의 block, 256 x 256 이미지를 생성하는 데에는 4개의 블록을 사용 )

하나의 벡터에 대해서 어떻게 진행되는지 시각화 해보면 위와 같고,
실제로는 16*16개의 벡터에 대해 한번에 진행된다.
3. 이후 Upsampling을 통해 크기를 키워서 최종적인 더 디테일이 추가된 고화질의 이미지를 생성한다.
4. 생성한 이미지에 대해 실제 이미지를 가지고 Discriminater를 학습하는 과정은
앞선 Stage-I GAN과 동일하다.
목적함수 설명

목적함수도 Stage-I GAN과 매우 유사하다.
다른 점이라면,
Generator의 입력으로 사용되는 정보는 랜덤 노이즈 벡터 z 기반이 아니라
s0라는 Stage-I GAN에서 얻은 이미지라는 것이다.
나머지는 동일하다.
위조범 입장(G)에서 학습할 때에는 위조범이 만든 이미지를 Discriminator가 진짜라고 인식해야 하고,
경찰 입장(D)에서 학습 할 때에는 Discriminator가 진짜 이미지를 진짜로 인식하고, 가짜 이미지를 가짜라고 인식해야 한다.

다시 도식을 보면 각 부분마다 어떤 과정이 진행되는지 한눈에 이해가 바로 될 것이다.
StackGAN++
StackGAN++는 StackGAN의 후속버전이다.

기존 StackGAN은 2번의 이미지 생성 과정을 거쳤더라면,
StackGAN++는 3번의 이미지 생성 과정을 거친다.
GAN에 넣을 때마다,
화질이 높아지고 64x64 -> 128x128 -> 256x256
디테일이 추가된다.

성능 비교를 해보니, 확실히 좀더 깔끔한 이미지들과
텍스트에 더욱 알맞는 이미지를 뽑아내는 것을 볼 수 있다.
'Computer Vision' 카테고리의 다른 글
| [GAN 시리즈] CGAN(Conditional Generative Adversarial Nets) 간단 정리 (0) | 2023.01.22 |
|---|---|
| [GAN 시리즈] GAN(Generative Adversarial Networks)에 대한 모든 것 (0) | 2023.01.20 |