[5-1] Six challenges(benchmarks) in NLP
NLP (natrual language processing) 에는 성능을 측정하기 위해 많이 쓰는 과제들이 있다.
Elmo에서 사용한 6개를 소개한다.
1. SQuAD (Standard Question Answering Dataset)
(독해 이해 reading comprehension)
입력 : context /question 쌍
출력 : answer , 정수 쌍
2. SNLI (Stanford Natural Language Inference)
(자연어 추론 language inference)
문장 (premise(전제) 와 hypothesis(가정))과
label (entailment(결과), contradiction(대치), neutral(중성))으로 구성
3. SRL (Semantic Role Labeling)
(문장 의미 파악)
문장의 중심적 의미와 관련하여 who did what to whom, when, why를 발견하는 것
qeustion 과 answer 쌍으로 구성
4. Coref (Coreference Resolution)
(동일지시어 결정)
문장 안에서 같은 의미(entity)인 모든 표현을 찾는 것
attention maechanism 사용
5. NER (Named Entity Recognition)
(개체명 인식)
개체명을 인식하여 구분하는 것
6. SST-5 (Stanford Sentiment Treebank)
(감정 트리뱅크)
문장의 감정을 분류할 수 있어야 한다 (ex 긍정, 부정)
트리구조로 내려가면서 분류 (Decision tree와 유사)
이와 관련해 emlo 논문에서 사용한 SOTA data는 다음과 같다.
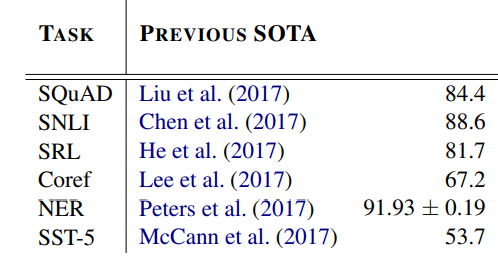
그 외에도
https://bluediary8.tistory.com/118
자연어처리(NLP)분야의 다양한 Task와 데이터
자연어처리 (Text) - 텍스트 (Text) : 텍스트 분야에서의 딥러닝 적용 또한 꾸준히 연구 되었습니다. 텍스트 분야는 세부 Task로 나뉘어 연구가 되었는데 대표적으로 다음과 같은 것 들이 있습니다. -
bluediary8.tistory.com
다음 링크에서 둘러볼 수 있다.